Collaborating
Overview
Teaching: 55 min
Exercises: 0 minQuestions
How can I use version control to collaborate with other people?
Objectives
Explain what remote repositories are and why they are useful.
Explain what branches are and how they are used.
Show how to work collaboratively on a remote repository using branches.

So far, we’ve seen how Version control can help us track the changes we make to our files, and to revisit any point in their history.
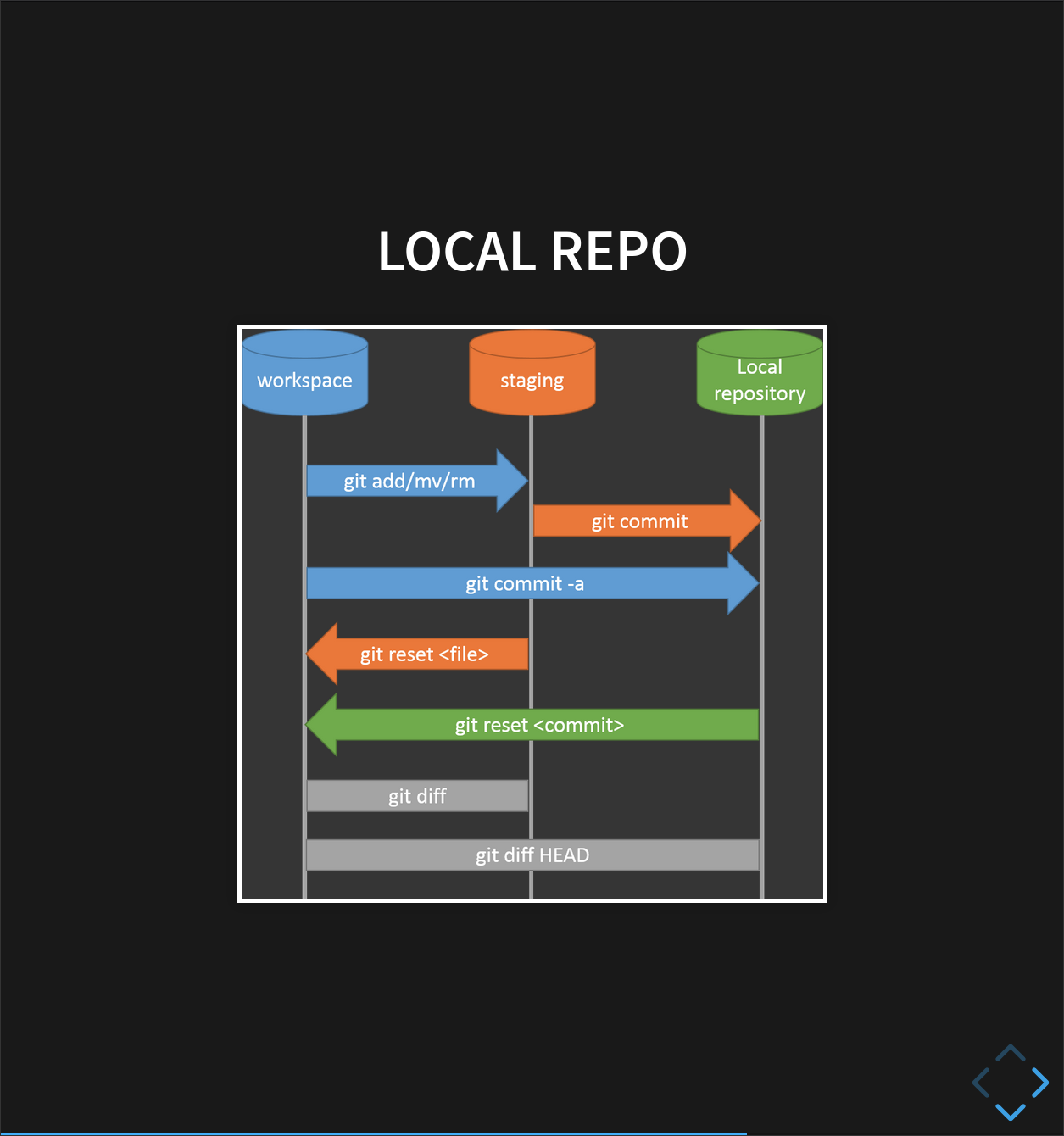
(there are a few extra commands we haven’t covered today for you to look at).
But, version control really comes into its own when we begin to collaborate with other people.

The missing link
We already have most of the machinery we need to do this; the only thing missing is to copy changes from one repository to another.
Systems like Git allow us to synchronise work between any two repositories.
In practice, though, it’s easiest to use one copy as a central hub, and to keep it on the web rather than on someone’s laptop.
Many programmers use hosting services like GitHub or GitLab to hold those master copies. In this example, we’ll use GitHub, but GitLab has all the same functionality.
Exploring the collaborative process
But first let’s explore the collaborative process.
So far we have been working in isolation. We’re going to use GitHub to set up a remote repository, so we can share our work or collaborate with others.

To GitHub!
Let’s start by sharing the changes we’ve made to our current project with the world.
Log in to GitHub,
then click on the icon in the top right corner to create a new repository called climate-analysis:
(You can also click on the ‘plus’ icon in the top-right and select New repository too)
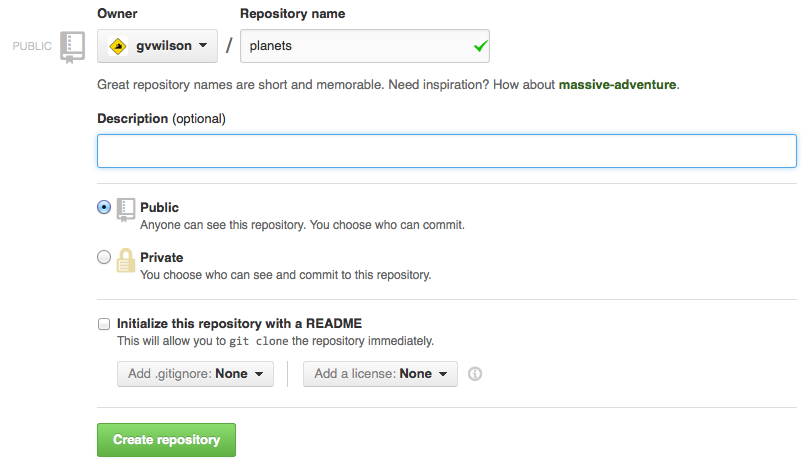
Name your repository “climate-analysis” You can optionally give it a friendly description and prove a README.md which is rendered on the front page of the web interface.
GitHub will host Publicly accessible repositories free of charge, but makes a charge for Private ones. However, researchers can apply for a free GitHub Pro upgrade via GitHub Education, which will allow you free unlimited private repositories. Your institute may also run a GitLab instance, allowing you to create your own private repositories.
You need to be sure that you really want to make your code publicly accessible, think about licensing, and that you’re not breaching the terms of any license of shared code by making it publicly available.
and then click “Create Repository”:
Connecting the remote repository
Our local repository still contains our earlier work on climate-analysis.py and temp_conversion.py,
but the remote repository on GitHub doesn’t contain any files yet:
The next step is to connect the two repositories.
We do this by making the GitHub repository a remote for the local repository. A remote is a repository conected to another in such way that both can be kept in sync exchanging commits.
The home page of the repository on GitHub includes the string we need to identify it:
Copy that URL from the browser, go back to your local repository, and run this command using your repository name not mine:
$ git remote add origin git@github.com:js-robinson/climate-analysis.git
The name origin is a local nickname for your remote repository:
we could use something else if we wanted to,
but origin is conventional, and will come in useful later.
The only difference should be your username instead of js-robinson.
We can check that the command has worked by running git remote --verbose:
$ git remote --verbose
origin git@github.com:js-robinson/climate-analysis.git (fetch)
origin git@github.com:js-robinson/climate-analysis.git (push)
Push commits from local to remote
Once the remote is set up, we can push the changes from our local repository to the repository on GitHub:
$ git push origin master
Counting objects: 10, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (10/10), done.
Writing objects: 100% (10/10), 1.47 KiB | 0 bytes/s, done.
Total 10 (delta 2), reused 0 (delta 0)
To github.com:js-robinson/climate-analysis.git
* [new branch] master -> master
The push command takes two arguments, the remote name (‘origin’) and a branch name (‘master’).
We’ll get to branches in a moment!
So, now our local and remote repositories are now in sync! You can check in your browser that the files have reached your GitHub repository.
Authentication options
Earlier, we cloned a repository using
https://to download it. You used to be able to push to a repository viahttps://too by entering a password, but last year that was disabled for security reasons. You might find some old tutorials still instruct you to use thehttps://format, but you can switch them togit@github.comwithout any problems.
Master and Main
GitHub is currently recommending users name their ‘core’ branch
maininstead ofmaster. Git defaults to creating amasterbranch when you make a new repo from the command line. We teachmasteras most existing repositories and examples use it, but you can follow GitHub’s instructions for how to rename your branch tomainif you would prefer.
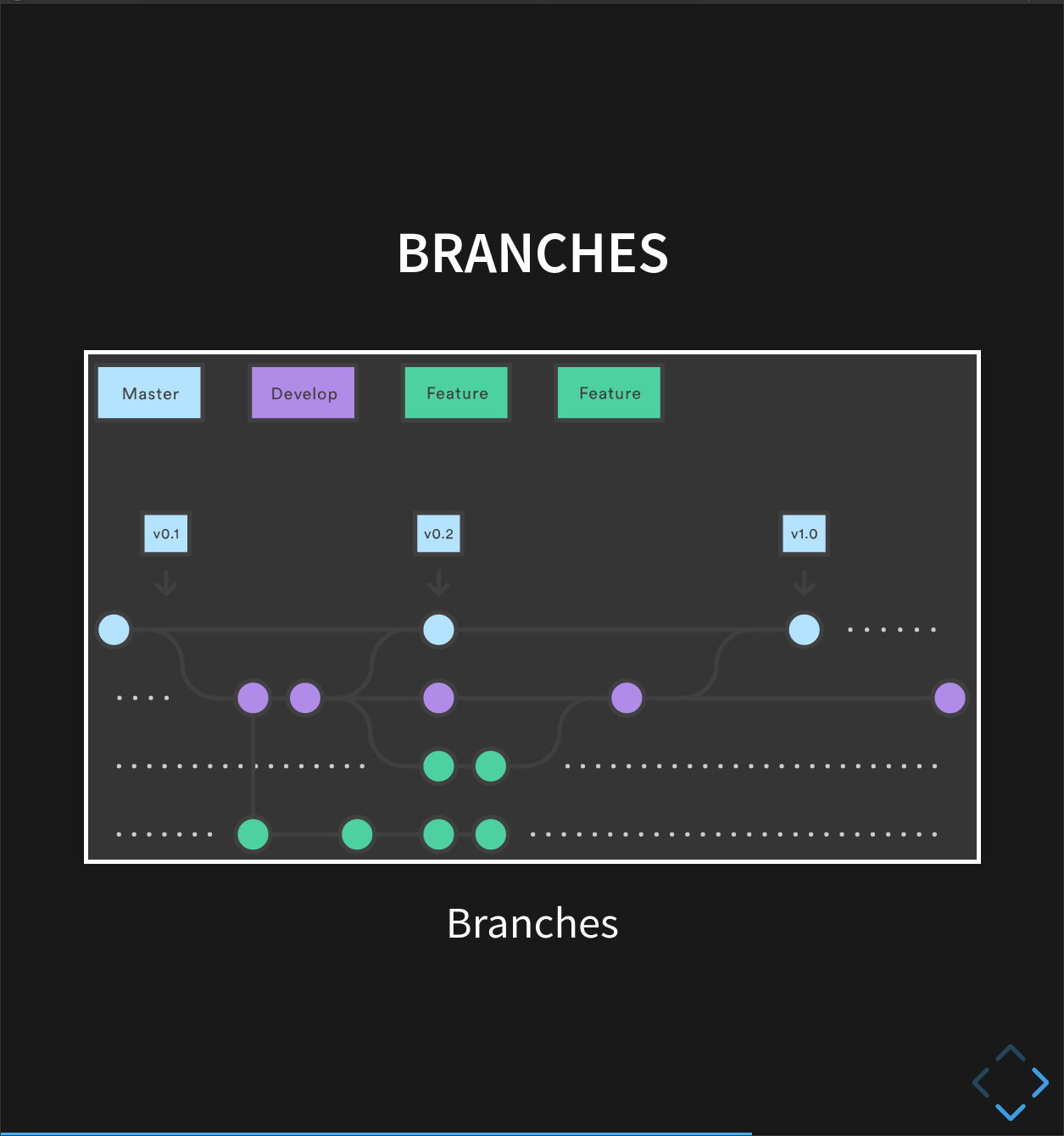
Introducing branches
Now we’ve shared our code with the world, and other people can download a copy of it- just like you downloaded a copy of the repository these lessons are in.
However, what happens if you want to keep working on it, adding new features to the code?
At the moment, there’s only one version of the code available online. If keep making changes and pushing them to GitHub, then anyone who downloads from there will get all of our work in progress- whether or not it’s ready to use!
Equally, we can’t wait until we’ve finished all our work before pushing it to GitHub either. We could lose weeks or months of work if our computer breaks!
We can avoid this by using the branches we mentioned earlier.
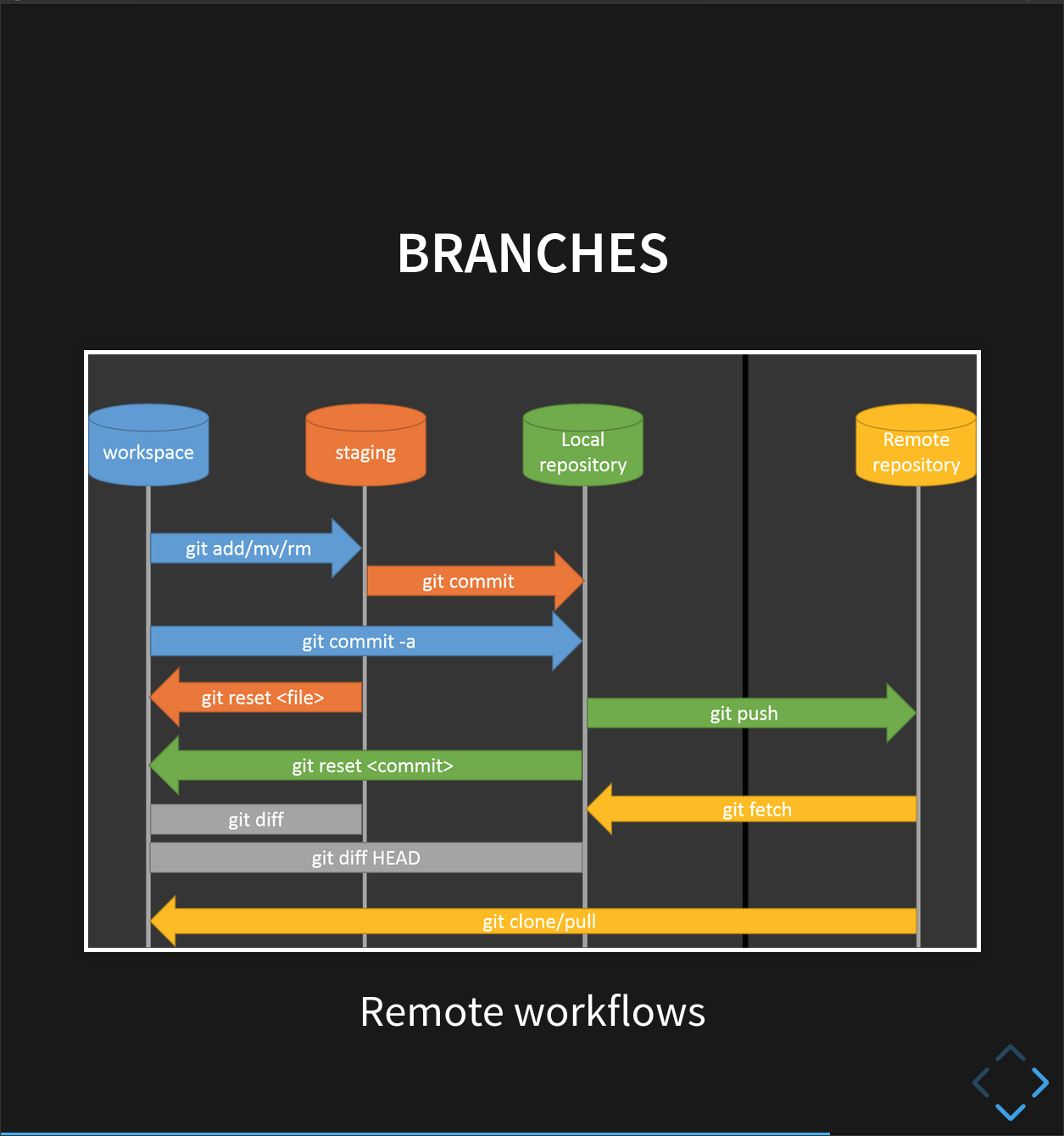
A branch is a different version of the files in your repository, that can contain its own set of commits. We can create a new branch, make changes to the code that we commit to the branch, and when we’re happy with those changes, merge them back to the main (‘master’) branch. Branches are commonly used as part of a feature-branch workflow:

In this workflow, we have a main (‘master’) branch which is the version of our code that’s test and reliable, and want to share- for example, the version of the code we used in a paper. When sharing code used in a paper, you can mention the specific commit that you used!
Then, we have a development (‘dev’) branch that we use for work-in-progress code. As we work on adding new features to the code, we commit the changes to our development branch.
(We’ll talk about feature branches later!)

Creating branches
Let’s create a development branch to work on:
$ git branch dev
This command doesn’t give any output, but if we run git branch again, without giving it a new branch name, we can see the list of branches we have- including the new one we just made.
$ git branch
dev
* master
So how do we switch to this new branch? We use git checkout again, but this time with the name of the branch instead of the name of a file:
$ git checkout dev
Switched to branch 'dev'
Uncommitted changes & branches
If we try and check out a new branch whilst we have changed but not committed any tracked files, then we’ll get an error message!
To fix this, make sure you commit your work before trying to check out a new branch. Make sure to give it a descriptive commit message for when you go back to it!

Committing to branches
Now we’ve created a ‘dev’ branch, we can start working on it without affecting our ‘master’ branch.
Lets expand our library of climate analysis functions by adding a new file:
$ nano rainfall_conversion.py
$ cat rainfall_conversion.py
"""A library to perform rainfall unit conversions"""
def inches_to_mm(inches):
"""
Convert inches to milimetres.
Arguments:
inches -- the rainfall inches
"""
mm = inches * 25.4
return mm
$ git add rainfall_conversion.py
$ git commit -m "Add rainfall module"
[dev 29f4a55] Add rainfall module
1 file changed, 10 insertions(+)
create mode 100644 rainfall_conversion.py
You might have noticed a change already. The commit message now reminds us we’re committing to the ‘dev’ branch.
Now, if we check the history, we can see this commit was added:
$ git log
commit 29f4a552f33bc4f26810c86b7cf7fafd2173034d (HEAD -> dev)
Author: Sam Mangham
Date: Tue Apr 28 13:42:23 2020 +0100
Add rainfall module
commit 5a1a72a418b4b13f7f783d2feae755de7a24580c (origin/master, master)
Author: Sam Mangham
Date: Tue Apr 28 13:22:17 2020 +0100
Add rainfall processing placeholder
commit 86bca165b4a1fb7028efbd88bd143deaced3ef9a
Author: Sam Mangham
Date: Tue Apr 28 13:21:30 2020 +0100
Add Docstring
commit 736c5eaf3219ae81b126534424bfd27604d2406b
Author: Sam Mangham
Date: Tue Apr 28 13:17:43 2020 +0100
Initial commit of climate analysis code
We can see the new commit to the dev branch in the log. Helpfully, the history also shows the point at which our new ‘dev’ branch broke away from the ‘master’ branch.
Let’s switch back to the ‘master’ branch and look at the directory again:
$ git checkout master
Switched to branch 'master'
$ ls
climate_analysis.py temp_conversion.py
We can see that the rainfall_conversion.py file we created on the ‘dev’ branch has disappeared. However, if you check out ‘dev’ again, it’ll reappear:
$ git checkout dev
Switched to branch 'dev'
$ ls
climate_analysis.py rainfall_conversion.py temp_conversion.py
Pushing & updating branches
Now we have a commit to our ‘dev’ branch, how do we get the changes from it into our ‘master’ branch? There’s a couple of ways of doing this, but first we’re going to do it using a pull request on GitHub.
First, we’ll push the contents of the ‘dev’ branch to GitHub the same way as we pushed the ‘master’ branch:
$ git push origin dev
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 467 bytes | 233.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
remote:
remote: Create a pull request for 'dev' on GitHub by visiting:
remote: https://github.com/smangham/climate-analysis/pull/new/dev
remote:
To github.com:smangham/climate-analysis
* [new branch] dev -> dev
Now our ‘dev’ branch is on GitHub! Let’s go and check it out. Just above the list of files on the left-hand side is a dropdown labelled ‘branches’. Select ‘dev’, and you should see the list of files change. Then, let’s click the “Compare & pull request” button.
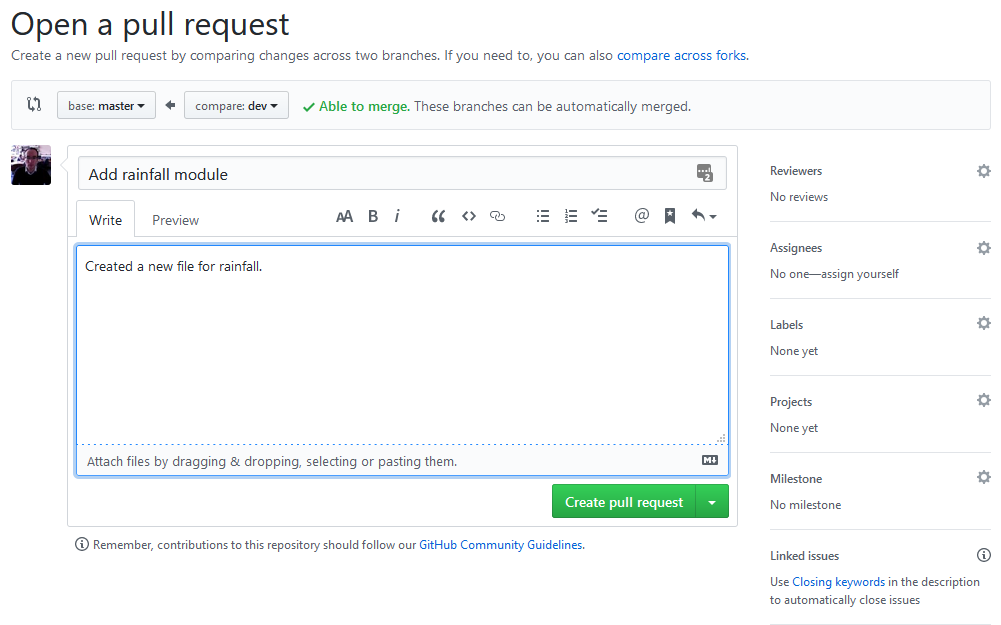
A pull request is a formal way to request to merge the changes from one branch into another, providing a message letting people know what your changes do. GitHub provides you with a range of tools to help manage pull requests.
If you’re part of a team, you can suggest reviewers for your code, just as you’d recommend reviewers for a paper. Getting extra eyes on your code can help spot any bugs or mistakes early on.
In addition, you can assign the pull request to someone. They’ll be notified that they’ve been assigned. This is useful if you’re in part of a team, and want to assign the pull request to someone else to handle any potential merge conflicts (we’ll get to those later).
Below this section of the pull request, you can see a list of changes this pull request would make. These is useful when reviewing code:
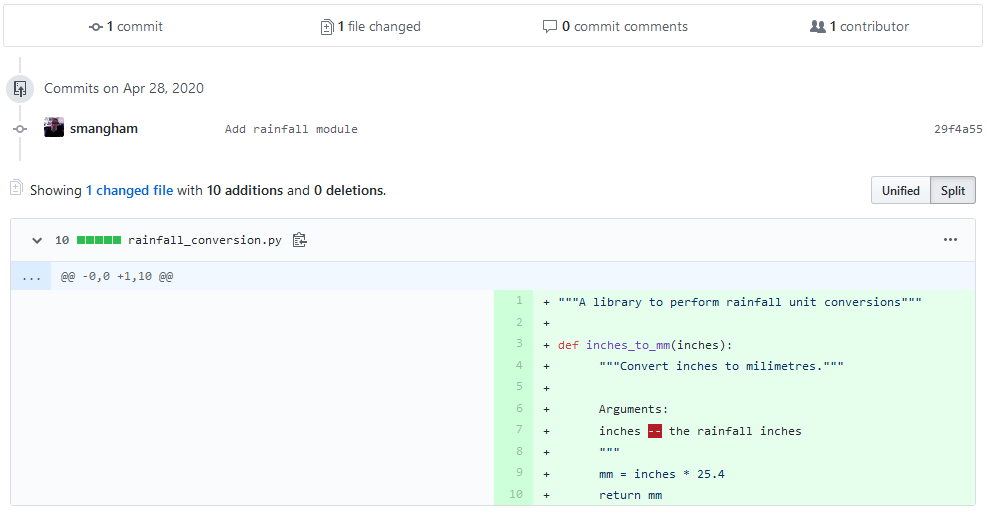
In this case, we can see one new file has been created.
Now, let’s click Create pull request:
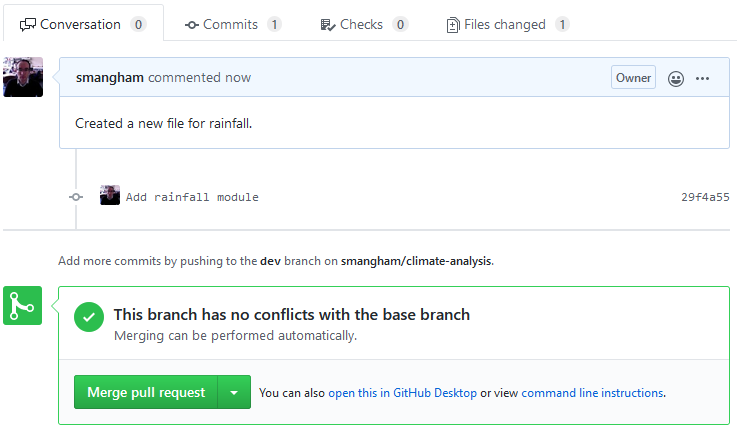
Fortunately, this branch can be automatically merged. Not all branches can be automatically merged. For example, if you had made more commits straight to ‘master’, if they edited the same lines in the same files as commits in ‘dev’ there would be a merge conflict.
It is possible to resolve merge conflicts on the command-line git, and we’ll cover it later.
Now we can click Merge pull request, and then add a commit message and click Confirm merge to update ‘master’!
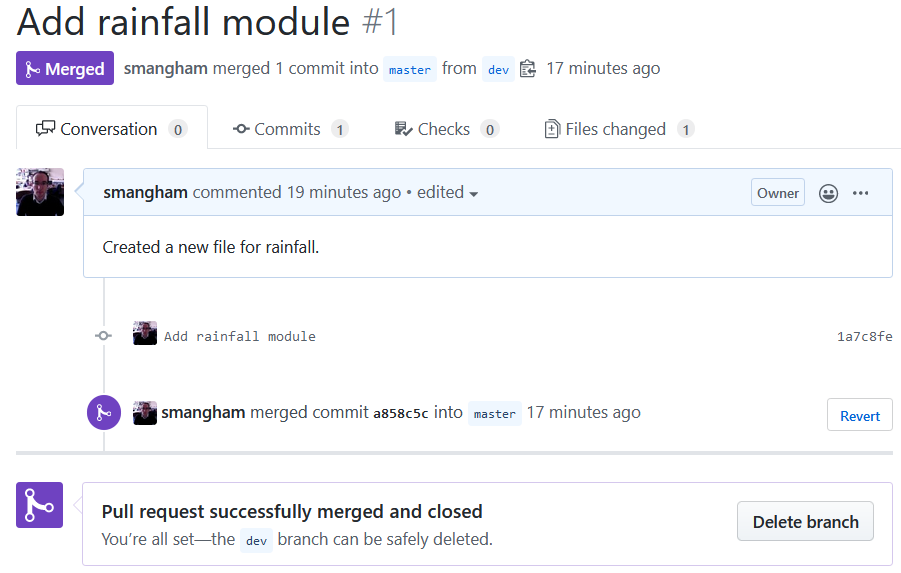
Now we’ve updated the ‘master’ branch on GitHub with our new work from the ‘dev’ branch! All we need to do is to update our local version. Let’s go back to our command line and check out the master branch, then pull our changes from GitHub to our computer:
$ git checkout master
Switched to branch 'master'
$ git pull origin master
remote: Enumerating objects: 1, done.
remote: Counting objects: 100% (1/1), done.
remote: Total 1 (delta 0), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (1/1), done.
From github.com:smangham/climate-analysis
* branch master -> FETCH_HEAD
5a1a72a..32fa979 master -> origin/master
Updating 5a1a72a..32fa979
Fast-forward
rainfall_conversion.py | 10 ++++++++++
1 file changed, 10 insertions(+)
create mode 100644 rainfall_conversion.py
Now we know how to create branches, remote repositories, and sync our local and remote branches up.

Feature-branch workflows
Now we know how to keep a seperate working copy of our code, and use it to update the version we want other people to use. But what if, whilst we’re working on adding a new feature in our development branch, someone finds a bug in our code? We don’t want to have to complete the new feature in ‘dev’ before we can start fixing the bug!
Plus, what if multiple people want to work on the code at once, each working on a new feature? If they’re all using ‘dev’, there’ll be plenty of merge conflicts. Plus, it makes testing the effect of the new features much harder - we only want to change one thing at a time!
This is where the feature-branch workflow we mentioned comes in! Remember the figure from earlier?
There’s a ‘master’ branch, a ‘dev’ branch, but also several feature branches.
When you want to make some changes to the code, like adding new features (or even fixing a complicated bug), you create a new feature branch. Then, you can work on your feature branch without worrying about conflicts or confusing others with work-in-progress files.
Once you’ve finished and tested your new work, then you can submit a pull request from your feature branch back to the ‘dev’ branch.
In some collaborations, only some people have permission to merge pull requests to the ‘dev’ and ‘master’ branches. This makes sure that nothing gets into the shared versions of the code without it being properly reviewed and tested by others.
When To Branch
The feature-branch workflow is incredibly helpful, but does add a bit of overhead. If you’re developing a new code from scratch, whilst you can create new branches for each sub-component of the code (and should if you’re collaborating with others), if you’re the only developer on a relatively small project you only need to start branching once you’ve got your first, working version of the code.
Whilst committing directly to the development branch can cause problems (e.g. other people branching off of unfinished work), if you’re working on something that takes less than a day or so and you can test fully (e.g. updating some documentation), it’s normally OK to do it as a single commit directly on ‘dev‘.

Exercise: Feature branches
Now let’s put the feature-branch workflow into practise!
The code needs some documentation so people know what it does.
Try creating a new branch coming off ‘dev’ called ‘doc’, then add a new file called
README.mdcontaining the text “Tools to parse and convert climate data from CSV”.Once you’ve done that, add and commit the file to your local repository, then push your changes up to GitHub. Then once they’re on GitHub, create a pull request, merge your new feature branch back into your development branch, and pull the changes to ‘dev’ back to your local repository.
Solution
$ git checkout dev $ git branch doc $ git checkout doc $ nano README.md $ git add README.md $ git commit -m "Added a readme file." $ git push origin docThen go to GitHub to do the pull request. Once that’s done:
$ git checkout dev $ git pull origin dev
Key Points
git remote add originlinks a local repository to a remote one and names it ‘origin’.
git pushcopies changes from a local repository to a remote repository.
git pullcopies changes from a remote repository to a local repository.Branches are versions of a repository that can contain different commits.
Pull requests on GitHub can be used to merge different branches together.
git clonecopies a remote repository to create a local repository with a remote called origin automatically set up.