Introduction
Overview
Teaching: 10 min
Exercises: 0 minQuestions
Why should I manage my software development?
Objectives
Explain why academic software development requires management.
Developing academic software can be an unusual exercise, especially compared to traditional software development.
Unlike in traditional development, the software itself often isn’t the end goal- it’s the papers it enables that are. This can lead to the focus being on how to get the results needed for the latest paper, without considering how this works in the long run. As a result, a large proportion of academic software is paperware- ad-hoc, poorly-written code made without any real plans, where all the information on how it works and how to run it is undocumented.
This usually means the code is harder for you to develop later, and hard for you to get collaborators on board to develop and/or use it. In the worst case, mismanaged software development can result in you having to rewrite from scratch. Given how much effort it takes to produce scientific software, this can be a huge waste of your time and effort!
Better Software, Better Research
One key reason to make sure you properly manage the development of your academic software, even when the software is just a by-product of doing the science, is because better software makes better research. Organisations like the Software Sustainability Institute exist to make this point.
If you plan your project out clearly in advance, openly list your future goals and the limitations of your software, and write code that’s consistent and designed to be easy-to-interpret, you’ll find it to be much more sustainable. Sustainable software is easier to keep maintained, to expand to cover new problems, and to bring in new collaborators on. The benefits to your research from this will rapidly outweigh the time you spend on software project management.
Single User-Developer Projects
Many academic software projects have pretty limited scale- often they’re run by a single user-developer, or just a small team. In these circumstances, it can be tempting not to spend the time on ‘user-facing’ project features like documentation. After all, everybody involved in the project has a deep grasp of the code and knows how it works and all the existing problems!
That’s not necessarily the case:
- You might want to bring a new PhD student or postdoc onto the project later, and they’ll have a much harder time getting started if all the information on the project lives within your head. Not only do they have huge areas of unknown unknowns, you will have large areas of unknown knowns- things that you’ve forgotten are essential to build the code, or edge cases it can’t cope with.
- The results of your research should be reproducible. That means that referees on your papers, or those who read them, should be able to take your code and re-create your results. If you write your project in a way that only you can use it, then you’re doing bad science.
- Knowledge can decay. Whilst you might know all the ins and outs of the code now, trying to come back to the project in two years’ time (when you’re writing it up in your thesis, or starting a new collaboration re-using it).
So as a result a lot of project management features that are designed to work as part of a team, or communicate information to users, are still useful for you as a sole user-developer.
The Bus Factor
One other reason it’s important to document how your code is developed, managed and used is to get your Bus Factor up. The bus factor describes the number of developers who have to be hit by a bus for a project to be impossible to continue. For a very large percentage of academic software projects, the bus factor is 1…
Even if you aren’t hit by a bus, accident, illness, family emergencies or other unplanned events (like global pandemics) can prevent you working on a project for a while. Fortunately, if you’ve documented your code, goals and the current status of your project collaborators can pick it up and get the results required for a referee response or conference presentation!
Project Management Tools
Fortunately, a lot of tools exist to help manage the development of your academic software. You should already be familiar with Git and GitHub, already a great way to keep track of how your code evolves and share it with others. GitHub and other repository hosting sites (for example, GitLab) have a whole range of project management tools that we can use- and we’re going to start with them.
Key Points
Well-made software is easier to expand and reuse
You need to produce reproducible research.
You are a user of your own code.
Issues
Overview
Teaching: 10 min
Exercises: 5 minQuestions
How can I keep track of bugs and problems?
How can I communicate them to users?
Objectives
Learn what issues are and how to use them.
Create an issue on GitHub.
As a piece of software is used, then bugs will inevitably come to light- nothing is perfect! If you work on your code with collaborators, or have non-developer users, it can be helpful to have a single shared record of all the problems people have found with the code- not only to keep track of them for you to work on later, but to avoid the annoyance of people emailing you to report a bug that you already know about!
Issues
GitHub provides a framework (as does GitLab!) for managing bug reports, feature requests, and lists of future work- Issues.
Go back to the home page for your climate-analysis repository, and click on the Issues tab. You should see a page listing the open issues on your repository, currently none.
We’re going to create a new issue, raising the problem that the functions to convert between inches and milimeters don’t work in our code.
When you create an issue, you can provide a range of details added to them. They can be assigned to a specific developer- this can be a helpful way to know who, if anyone, is currently working to fix an issue (or a way to assign responsibility to someone to deal with it!).
We’re going to assign this issue the label Bug, by clicking on the cogwheel by the Labels section on the right hand column, then submit the issue.
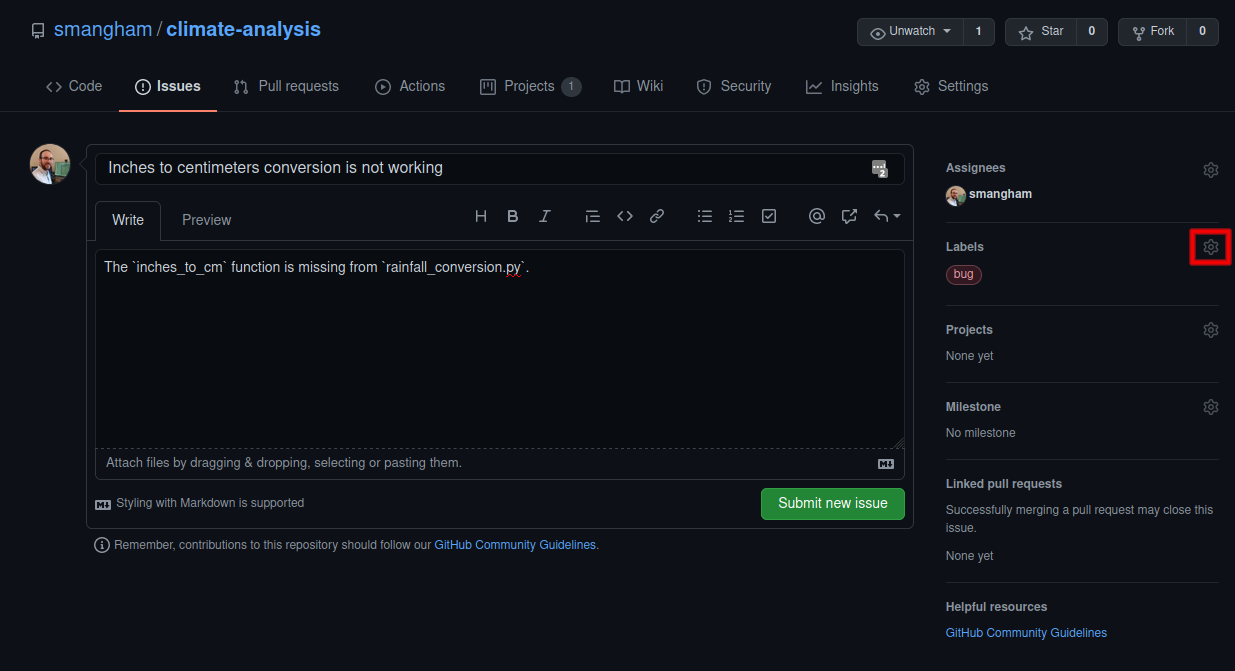
The labels available for issues can be customised, and given a colour, allowing you to see at a glance from the Issues page the state of your code. The default labels include:
- Bug
- Documentation
- Enhancement
- Help Wanted
- Question
The Enhancement label can be used to create issues that request new features, or if they are created by a developer, indicate planned new features. The Bug label makes the code much more usable, by allowing users to find out if anyone has had the same problem before, and how to fix (or work around) it on their end. Enabling users to solve their own problems can save you a lot of time and stress!
The Enhancement label is a great way to communicate your future priorities to your collaborators, and also your future self- it’s far too easy to leave a software project for a few months to write a paper, then come back and have forgotten the improvements you were going to make. If you have other users for your code, they can use the label to request new features, or changes to the way the code operates. It’s generally worth paying attention to these suggestions, especially if you spend more time developing than running the code. It can be very easy to end up with quirky behaviour because of off-the-cuff choices during development. Extra pairs of eyes can point out ways the code can be made more accessible, and the easier a code is to use, then the more widely it will be adopted and the greater its impact will be.
Having open, publicly-visible lists of the the limitations and problems with your code is incredibly helpful. Even if some issues end up languishing unfixed for years, letting users know about them can save them a huge amount of work attempting to fix what turns out to be an unfixable problem on their end. It can also help you see at a glance what state your code is in, making it easier to prioritise future work!
You Are A User
This section focuses a lot on how issues can help communicate the current state of the code to users. As a developer, and possibly also the only user of the code too, you might be tempted to not bother with recording issues and features as you don’t need to communicate the information to anyone else.
Unfortunately, human memory isn’t infallible! After spending six months writing your thesis, or a year working on a different sub-topic, it’s inevitable you’ll forget some of the plans you had and problems you faced. Not documenting these things can lead to you having to re-learn things you already put the effort into discovering before.
Should Old Issues Be Forgot
Information decays very quickly. Try and remember all of the problems you had with a code you worked on a few years ago, for example your undergraduate final project. Were there any combinations of input settings that it couldn’t cope with, for example?
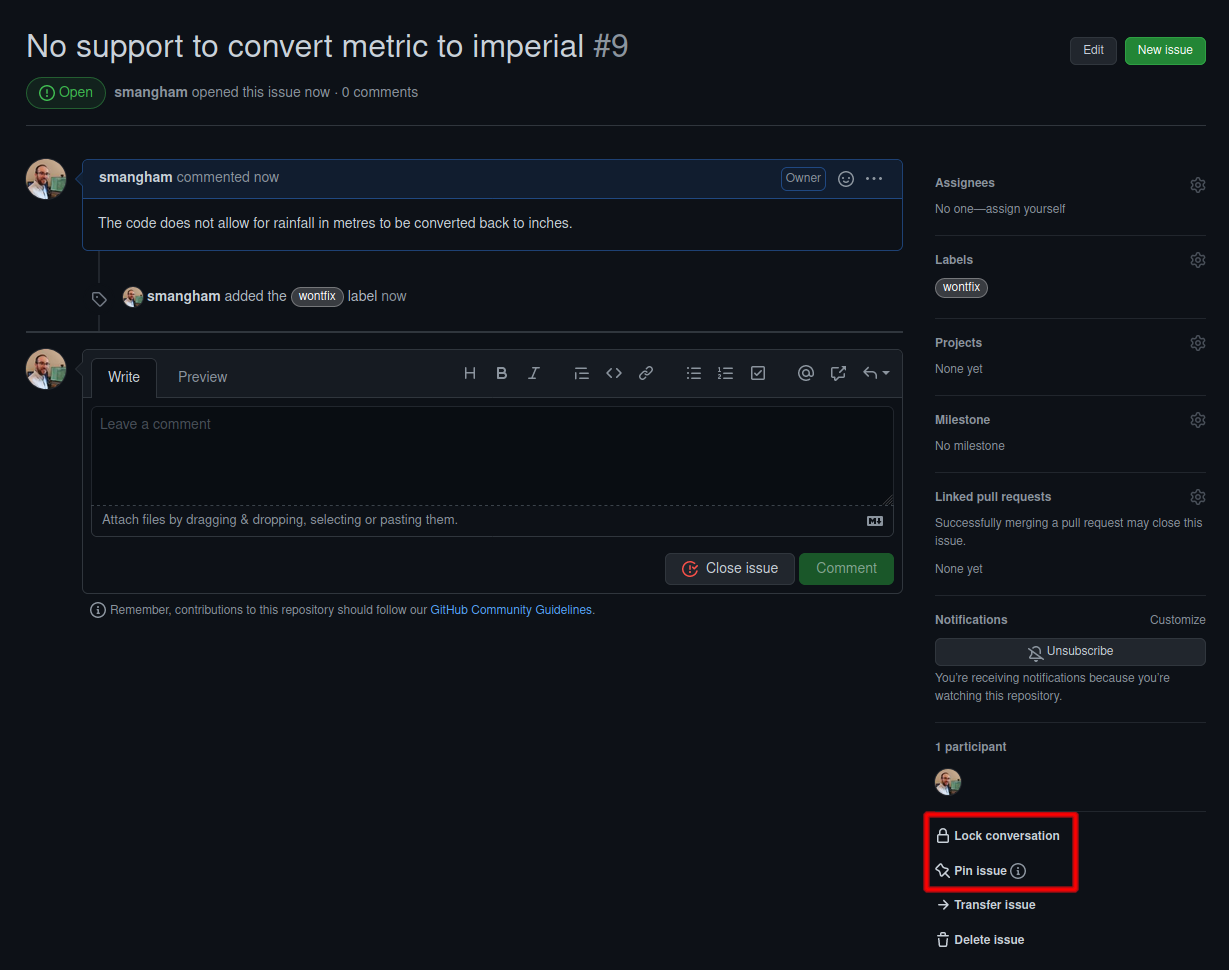
Wontfix
One interesting label is Wontfix, which indicates that an issue simply won’t be worked on for whatever reason- maybe the bug it reports is outside of the use case of the software, or the feature it requests simply isn’t a priority.
The Lock issue and Pin issue buttons allow you to block future comments on an issue, and pin it to the top of the issues page. This can make it clear you’ve thought about an issue and dismissed it!
Issue Templates
Whilst many academic software projects have only user-developers, for others many of the users will not have any experience working on the code, and in some cases not even have any software development experience at all.
Getting them to raise issues in a way that’s clear, helpful and provides enough information for you to act on (without going back and forth to extract it) can be hard. Fortunately, GitHub provides Issue templates. These allow you to set a template that anyone raising an issue is prompted to fill in. GitHub provides a range of default templates, but you can also write your own.
If you have a project with a large number of user-submitted issues, consider setting up issue templates. For more information on them, check out the GitHub documentation here.
Mentions
As lots of bugs will have similar roots, GitHub lets you reference one issue from another. Whilst writing the description of an issue, or commenting on one, if you type # you should see a list of the issues and pull requests on the repository. They are coloured green if they’re open, or white if they’re closed. Continue typing the issue number, and the list will narrow, then you can hit Return to select the entry and link the two. You can also navigate the list with the ↑ and ↓ arrow keys.
If you realise that several of your bugs have common roots, or that one Enhancement can’t be implemented before you’ve finished another, you can use the mention system to indicate which. This is a simple way to add much more information to your issues.
You can also use the mention system to link GitHub accounts. Instead of #, typing @ will bring up a list of accounts linked to the repository. Users will receive notifications when somebody else references them- you can use this to notify people when you want to check a detail with them, or let them know something has been fixed (much easier than writing out all the same information again in an email!).
Linking Issues
Whilst we’ve documented that
inches_to_cmis missing,inches_to_mis still missing too. Try to raise a new issue, labelled as a bug, that mentions your previous issue and links to your GitHub account to reference that you are going to be handling it as both are similar.Then, check out the first issue you raised and see if anything has happened.
Commits
Mentions also work in commit messages! If you reference issue numbers in your commits (e.g. git commit -m "Fixes issue #65") then GitHub can automatically close issues, and will link the commit to the issue. This makes it easy for you to keep track of the changes to the code that were made in order to fix any given issue, should a similar bug crop up again in future.
Key Points
Issues are a way of recording bugs or feature requests.
Issues can be categorised by type.
Issues can reference other issues, and be referenced by commits.
Project Management
Overview
Teaching: 25 min
Exercises: 5 minQuestions
How can I manage the development of my code?
Objectives
Explain how project boards work.
Explain how to set up a Kanban board on GitHub.
Discuss strategies for using a Kanban board.
Explain what a fork is, and how to fork a repository.
Developing academic software is a project, and most projects (software and non-software alike!) consist of multiple tasks. Keeping track of the list of tasks you have to do, and how far you are through each, quickly becomes a non-trivial task itself. Without a good framework, it can be hard to keep track of what’s done, or what needs doing, and particularly hard to convey that to others or share the responsibilities out.
Project boards
A project board (or kanban board, from the japanese for a card) is a tool for keeping track of all the different components of a project, and what their current status is. They do this using columns and cards- you break your project down into tasks which you write on cards, then move them between columns that describe the status of each task. Cards are usually small, descriptive and self-contained tasks that build on each other- think “Add reader for .csv files” instead of “Get input working”. Breaking a project down into clearly-defined tasks makes it a lot easier.
In industry, they often use formal project management styles for their boards with specific columns and usages, but we’re going to use a simple, flexible format- not least because the more complicated your project board gets, the harder it is for you to get your collaborators to use it…
To GitHub
There’s a lot of sites that host project boards. For non-software projects like thesis-writing or organising conferences, you might use Trello, but repository hosting sites like GitHub and GitLab have built-in project boards that interact with the other features of the site, so we’re going to use them (though other tools like Jira also offer this functionality). This episode will use GitHub as an example, but GitLab has almost identical functionality.
From the ‘Project’ tab on GitHub, we can start up a board with Create a new project. A repository can have multiple project boards on it- for example, if multiple PhD students have their own project working on a code, each can have a project board for their own changes, or you can create a new board for each paper.
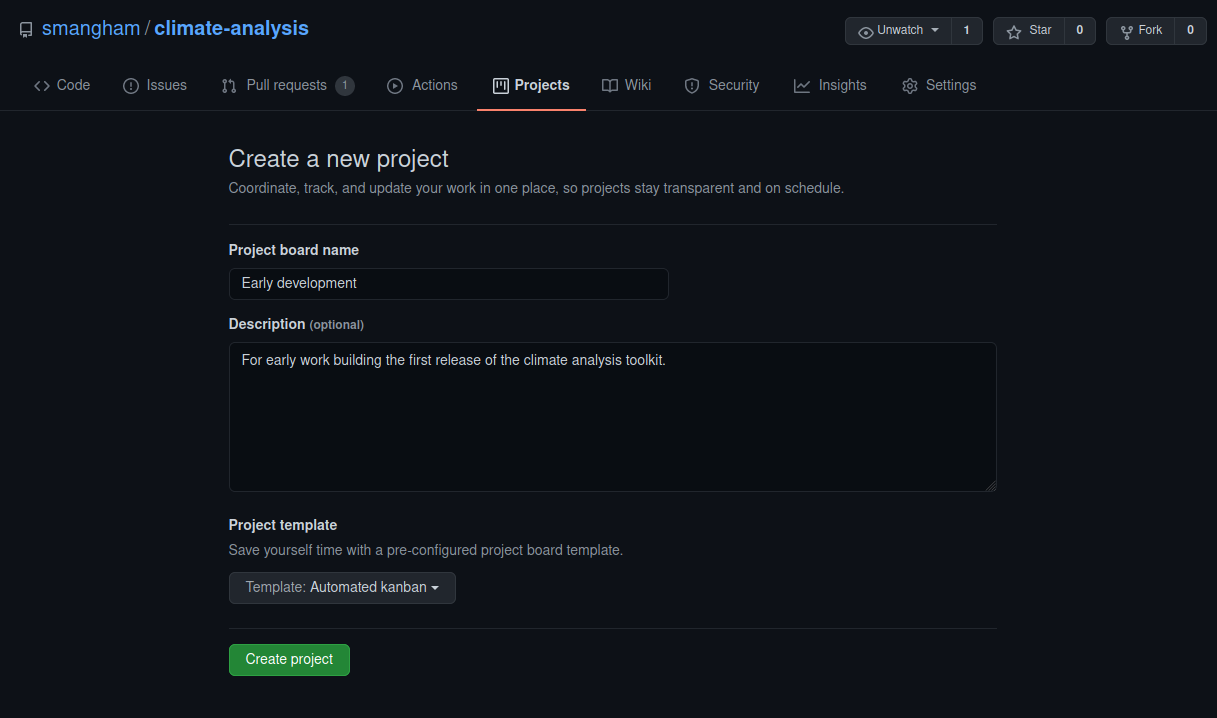
First, we need to give our project a name, e.g. “Early development”. Then, we can think about the columns.
Columns
Almost all styles of board have three ‘basic’ columns, with pretty self-explanatory names:
- To Do
- In Progress
- Done
GitHub provides template boards that automatically have those columns- and more, it has automated templates. If you add a pull request to the board, it can automatically move it to ‘Done’ for you when you merge it. We’re going to select the Automated kanban template, then Create project.
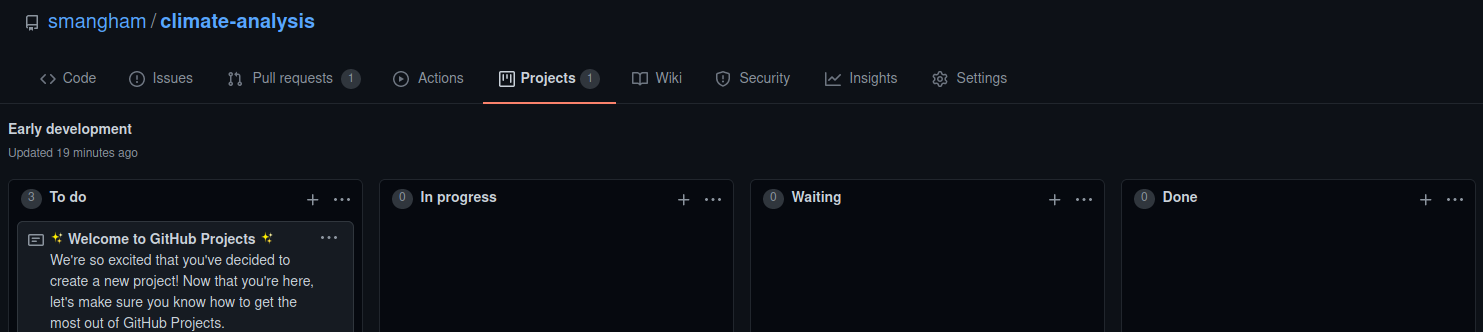
One common extra column is On hold or Waiting. If you have tasks that get held up by waiting on other people (e.g. to provide you with data or respond to your questions) then moving them to a separate column makes their current state clearer. We’re going to add a Waiting column, and drag it in-between In Progress and Done.
Cards
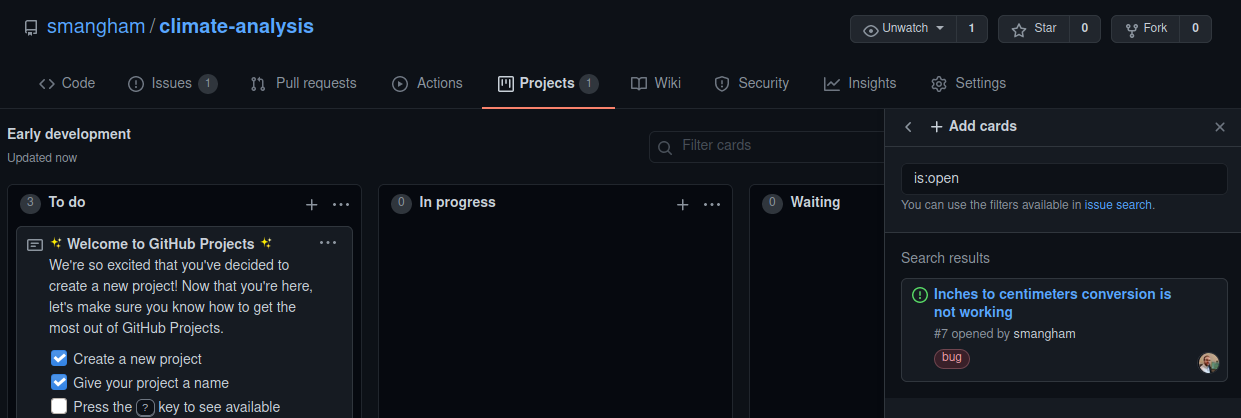
One of the advantages of using GitHub or GitLab to host your project board is the integration with issues. You can easily add issues to your project board, to keep track of how they’re progressing.
You can create cards on the project board, or you can import existing issues. Let’s add the issue we created last episode to the To Do column- click Add card and drag it over.
We can also create a card without an issue. The repo currently doesn’t tell people how to use the code- it needs an example. So let’s clear out the default cards GitHub adds using the … button and create a new one in To Do using the + button.
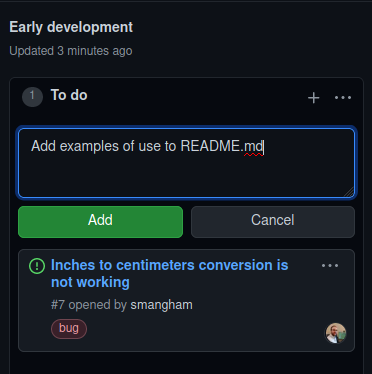
Notes can have detailed content like checklists, but that only goes so far. Later on you might want to convert the card to an issue so you can add labels or write detailed comments. Fortunately, you can use the Convert to issue option you just saw in the … menu. It’s often a good idea as you can use the comments section on the issue to write everything you tried- and, importantly, everything that failed for future reference.
Sometimes, a card you thought was simple and self-contained might turn out to be a bigger task than you thought. In that case, it’s sensible to create new cards that reference the one they broke off from.
Our project board is looking a little thin, but for an example full one check out the plotting library Plotly.
Labelling
You can see that your issue card has a ‘bug’ label, but the one you made has no labels. Convert your new card to an issue, and add the Documentation label to it.
Prioritisation
Once your project board has a large number of cards on it, you might want to begin priorisiting them. Not all tasks are going to be equally important, and some will require others to be completed before they can even be begun. Common methods of prioritisation include:
- Vertical position: The vertical arrangement of cards in a column represents their importance. High-priority bugs go to the top of To Do, whilst tasks that depend on others go beneath them. This is the easiest one to implement, though you have to remember to correctly place cards when you add them.
- Priority columns: Instead of a single To Do column, you have two or more- a To Do: Low Priority and a To Do: High Priority. When adding a card, you pick which is the appropriate column for it. You can even add a Triage column for newly-added issues that you’ve not yet had time to classify. This format works well for project boards devoted to bugs.
- Labels: If you convert each card into an issue, then you can label them with their priority- GitHub lets you create new labels and set their colour. Green low, orange medium and red high priority labels make for a very visually clear indication, but require the most admin as each card has to be an issue to receive a label.
Prioritisation
Currently, we don’t really have enough cards to prioritise. Create a new card named “High priority”, and using one of the prioritisation schemes arrange your board so it’s the most important.
Advanced Schemes
Whilst you can prioritise your tasks using simple schemes, more advanced ones exist in industry. MoSCoW (Must, Should, Could, Won’t) is one such scheme, which splits your tasks up into no more than 60% must-have features, and no less than 20% could-have features.
If your must-have features take longer than expected to implement, you have a pre-made list of what you can cut to complete the project on-time. If you have a relatively well-defined project that needs to be completed to a strict deadline, consider looking into MoSCoW.
Feature-branch workflows
We discussed feature-branch workflows yesterday, and they’re a key part of good project management.

There’s some best practise associated with the workflow:
- When adding a new feature, use a feature branch, and test the feature in your feature branch.
- It’s OK to commit broken, work-in-progress code to a feature branch as it’s not expected to be ‘finished’ until you submit a pull request.
- Once your feature is tested and it’s ready to merge, submit a pull request to
dev. - Don’t commit broken, work-in-progress code to
dev! If someone wants to make a new branch, or fix a bug, they’ll be usingdevas a base, so it needs to work fine. - Only pull from
devtomasterwhen you thinkdevis stable. This is the version people will be downloading to verify the results from your papers.
In industry, there’s normally strict testing criteria for when you merge in feature branches or merge dev into master.
That’s a lot harder to apply in academia- in an experimental code, there is often no known ideal behaviour to test against,
and you expect your code’s output to change as you alter the equations and assumptions.
Forks
‘Forking’ a repository is similar to creating a new branch, but on a much larger scale- you create your own copy of the whole repository, that is linked back to the original.
For some large projects, or open-source projects, it’s not practical to have all the collaborators working on the same repository. Multiple different developers might both create branches with the same name, leading to conflicts, and developers can end up with access to dozens of work-in-progress branches they don’t know anything about. Others limit the ability of unauthorised users to push to the repository to prevent abuse, or accidental uploads of sensitive or restricted material. In these contexts, it makes more sense for every collaborator to have their own fork. Then, once they finish work on a feature branch, they can submit a pull request back to the original.
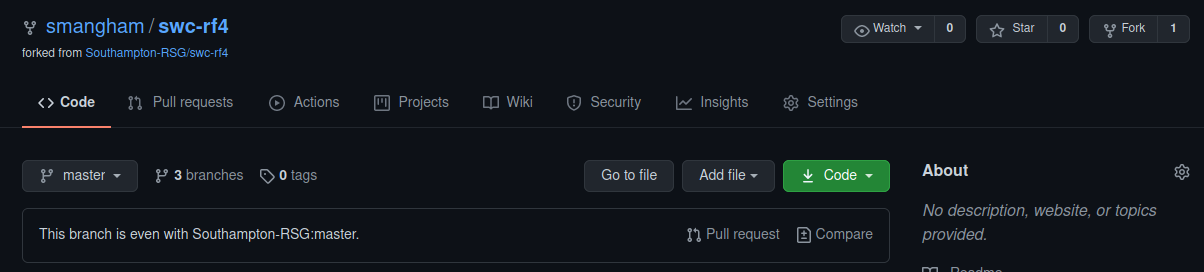
We’re going to create a fork of an existing repository- swc-rf4. Go to the repository on GitHub, and click Fork. You can fork a repository to your own account, or any Team you have access to. For now, we’ll clone a personal copy.

As you can see, the fork looks and works just like a normal repository, but handily tells you how far you are behind the original.
You may also be able to use forks to create modified versions of existing codes that better suit your needs, depending on their software license. It is good practise to submit your modifications and improvements back to the original, though.
Key Points
Projects are broken-down into self-contained tasks.
Tasks are represented as cards on a board.
Cards are arranged to show their status.
Issues can be added to project boards and labelled.
Project boards can show the priority of their tasks.
Forks are copies of entire repositories that can be synced up with the original.
Release Management
Overview
Teaching: 20 min
Exercises: 0 minQuestions
How can I manage the release of my code?
Objectives
Explain how to create stable releases for software
Explain how to generate a DOI for your software
Explain software licenses, and how to apply them
Whilst managing the development of software is essential to produce good code, managing the distribution and release of the software is essential to produce impact. If your code can’t easily be found, used or worked on by collaborators, then the impact of your development work will be dramatically limited. Fortunately, repository hosting sites like GitHub and GitLab offer a wide range of tools to help.
Releases
It is vitally important to cite your software. Software represents a huge expenditure of research time and energy, that is often invisible due to lack of citation. Many large software projects that underpin whole research communities are run by volunteers, because with no citations the work of the developers behind them is invisible to funders and institutions.
However, when software is cited, it’s often done poorly, creating a barrier to reproducibility. Often, as a software project evolves, the needs change- input files are expanded to take extra data, or output files are rearranged. Techniques are refined, and bugs are fixed. The end result of this is that frequently research done with older versions of the code cannot be reproduced with newer versions. Just referencing your software in your paper is equivalent to referencing a methods section that’s constantly being rewritten.
Fortunately, git commits provide you with a snapshot of the state of your software at a single point in time. We can avoid these problems by specifying which commit we used for a paper. Actual commit IDs, though, are a bit clunky to work with and commit messages are normally more focused on specific code changes than the scientific state of the code. Fortunately, GitHub and GitLab make it easy to create releases. A release is just a label for a specific version of the code.
If we create a new release when we arrive on the final version of the code we’re using in a paper, we can cite that specific version of the code- and anyone who wants to reproduce our work can easily get access to the version we used. We should make releases whenever we have a version of the code that’s stable and reliable enough we would be happy to share it with others.
Releases fit into the feature-branch workflow we discussed earlier. In this you have two key branches, master and development. You create branches off your development branch to work on new features, then when they’re relatively stable, you merge them back into the development branch. Then, after you’re happy the development branch is stable and reliable, you merge it back to the master branch. It’s those commits to the master branch that can become your releases.
To GitHub
If you go back to your climate-analysis repository homepage, you can use the Create a new release link. We just need to give the release a name, description, and a tag.
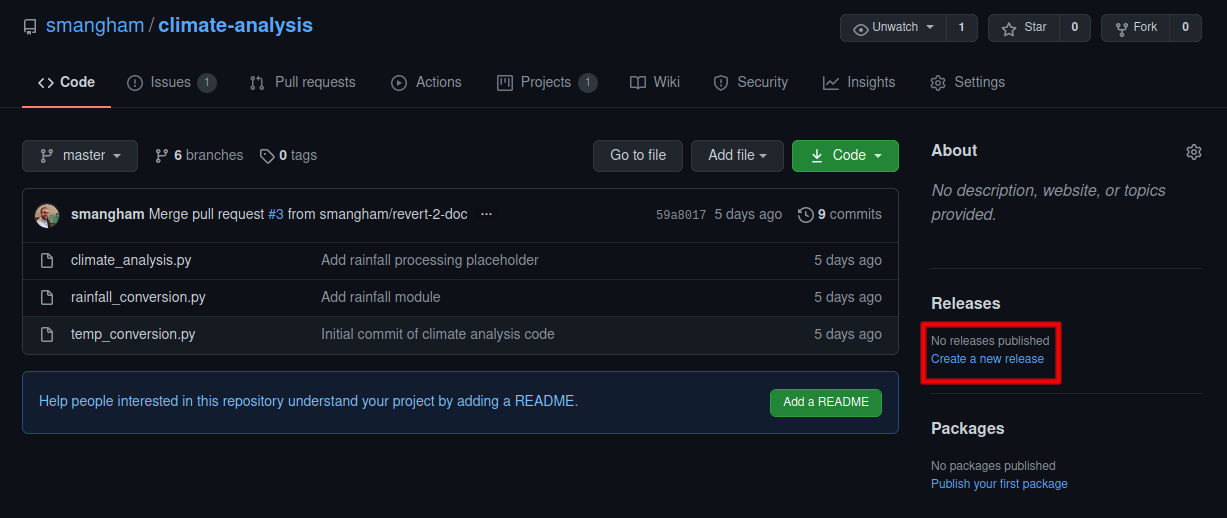
Make sure you select to create a release on the master branch. You can do releases of your development branch for internal use, but you should always make sure your code is stable enough to go on your master branch before you cite it.
Whilst the name is often descriptive or a project-specific codename, the tag is usually a sequence of numbers. There are a range of strategies for tagging releases, but the most common is to tag a release in the format of v1.0.0. Then:
- If you fix some bugs and perform a release, increment the last number, e.g.
v1.0.0tov1.0.1. - If you add some new functionality in a backwards-compatible way, then increment the second-to-last number and reset the last number, e.g.
v1.0.1tov1.1.0. - If you change your code so much it’s no longer backwards compatible (for example, your input files require a new variable so it can no longer run older ones), then increment the first number and reset the others, e.g.
v1.1.0tov2.0.0.
This lets your collaborators know when they can safely update without breaking their ongoing work!
Limitations of releases
If our code has dependencies like Python modules, we need to make sure that we include information on the specific versions of the dependencies too when creating a release. Python is well set-up to deal with this, as it can use
pip freezeto produce arequirements.txtfile with the current version of all the modules you’re using.For more complicated dependencies, there are a range of approaches. The simplest is to list the versions of your dependencies in your
README.md. Depending on the software licences of your code and its dependencies, you may be able to package them in your repository.For low-level codes, you’ll also need to list the compiler versions and architectures used. High-performance codes can be very dependent on compiler and library versions, so simply listing “GCC and OpenMPI” can cause a lot of pain. Instead, use the output of calling the compilers with the
-vor--versionflag to make sure you’re getting the correct information, e.g.gcc version 9.3.0.Bear in mind, though, that you will need to keep this information up to date if your dependencies change. ‘Stale’ documentation can be almost as bad as no documentation.
Issuing DOIs
Releases make it easy for others to reference a specific version of your code. However, if you want to track those citations, and to add the work to your academic profile on sites like ORCID, you’ll want a digital object identifier (DOI) for your release. Many Universities have internal systems for issuing DOIs for software, managed by libraries or research output administrative teams. Alternatively, Zenodo allows you to upload datasets, presentations or other files to get a cached version with a specific DOI, and automatically links the DOIs to your ORCID account.
Zenodo has great integration with GitHub, allowing you to automatically generate a DOI for any new releases on a repository. GitHub provide a very clear guide on how to do this: Citable code. Note, however, that Zenodo can only issue DOIs for publicly-visible repositories. This can be a problem if you need to keep your code private due to industrial collaborations.
Zenodo offers a ‘sandbox’, where you can test the process for creating a new DOI (as creating a DOI on their proper website is irreversible!).
We’ll use the sandbox at sandbox.zenodo.orgto create a DOI for our climate-analysis repository by registering it via Zenodo’s GitHub link and creating a new release on GitHub.
First, making sure we’re on sandbox.zenodo.org, we need to sign up using our GitHub account - using Log in or Sign up, and and selecting GitHub.
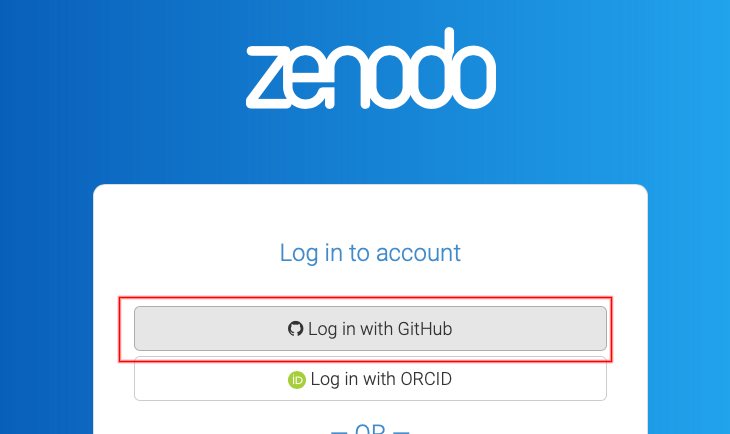
Once you’ve logged in, selecting GitHub from the drop-down menu
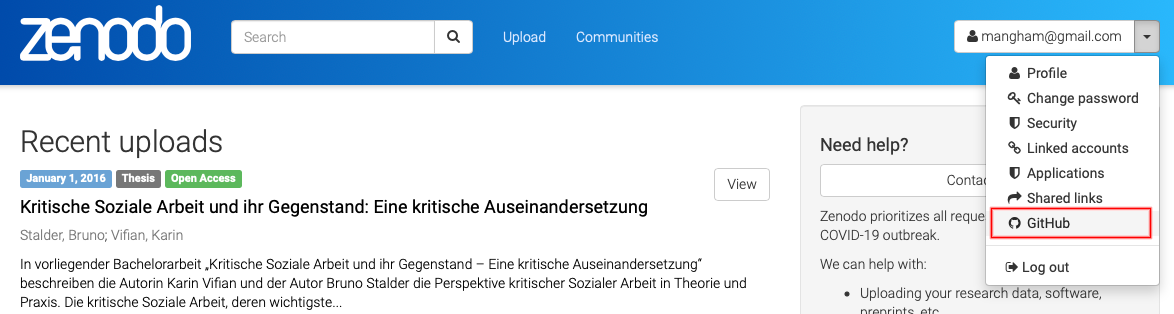
opens a list of your repositories, and we can toggle them to ‘on’ to begin tracking releases on them.
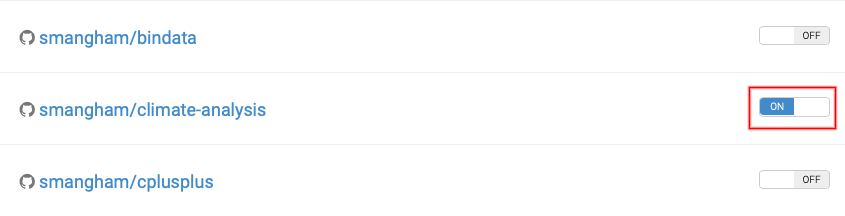
Zenodo won’t retroactively generate DOIs for releases, so we need to head back to GitHub, and create a new release, then go back to Zenodo and click on our repository to see the status of our upload.
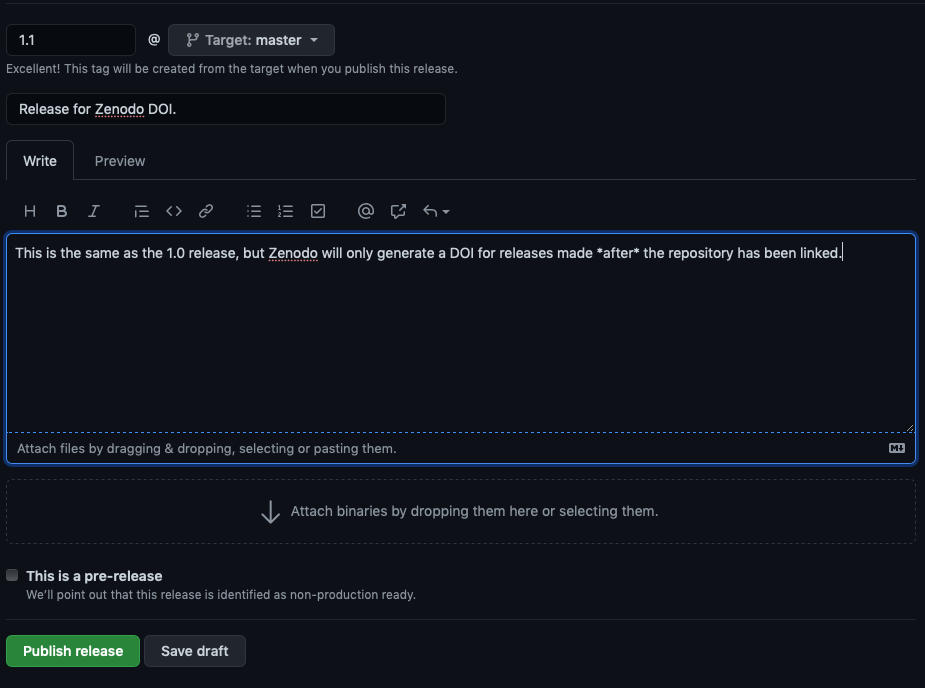
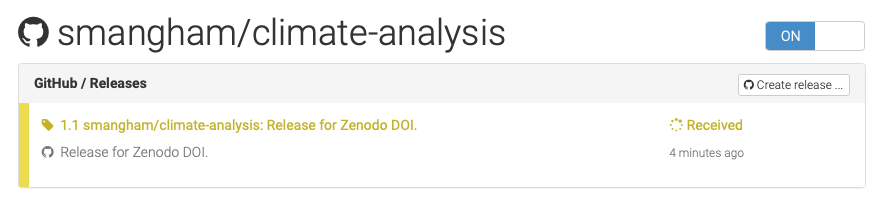
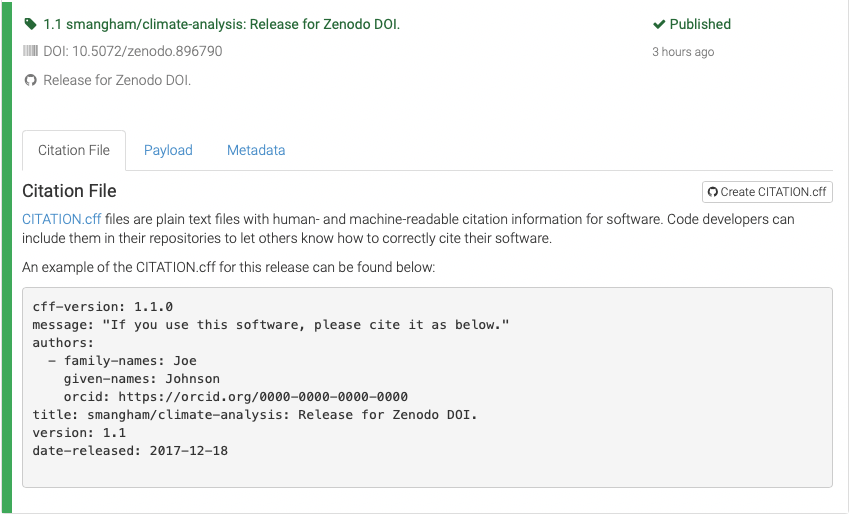
Depending on how busy Zenodo is, this can take anything from minutes to hours to process. Once it’s done, though, you get a DOI, which we can then edit into the message for our release.
Chickens and Eggs
There’s one slightly annoying quirk with using Zenodo to generate DOIs; you only get the DOI after creating the Release for a commit.
This means you can’t put the DOI for a commit in the
README.mdor aCITATION.cfffile for that commit. Unfortunately, there’s not really a good way around this! A work-in-progress project called Zenodraft is aiming to provide a solution by pre-reserving DOIs, and Zenodo say they are looking into the issue further.
Citation Files
You’ll have noticed the Zenodo upload gives you a template CITATION.cff file.
This is a handy way of letting people who use your code know how you’d like to be cited.
There’s more detail on these files here,
but one of the most important features is the ability to add your ORCID,
to easily link you to your code in a way that’s not dependent upon your university email address.
You can also request users cite multiple DOIs - for example, the DOI of a commit, and one of a
release paper.
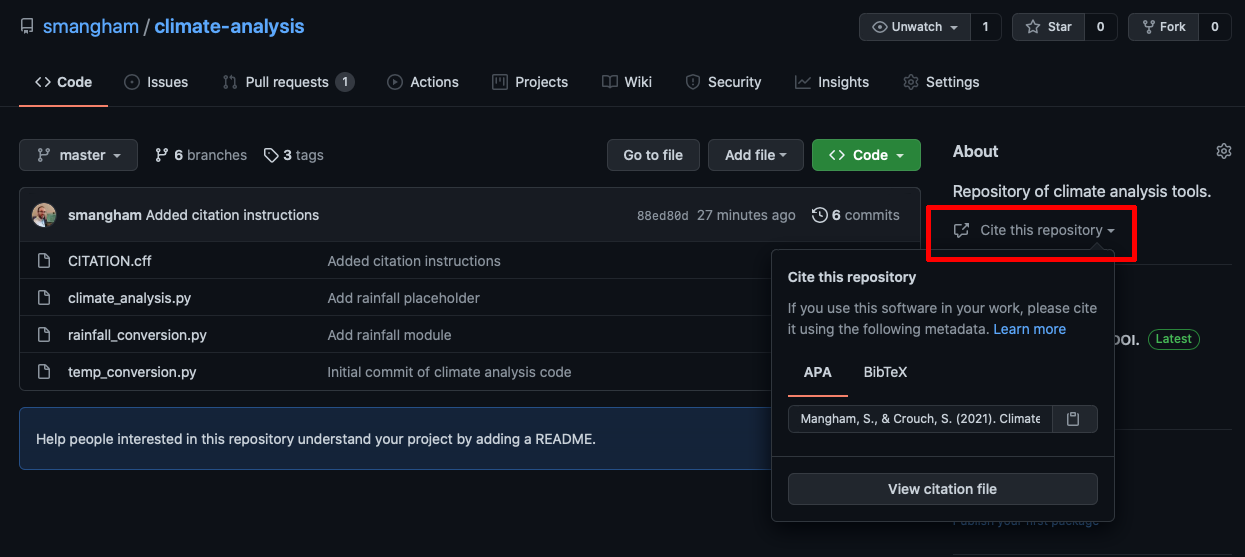
GitHub now also supports CITATION.cff files. A repo with one will have a button informing users of
how to cite it, and providing a pre-made BibTex citation.
Adding a CITATION.cff
Using the template from Zenodo, add a
CITATION.cfffile to your repository, then push it to GitHub.Solution
Contents of
CITATION.cff:cff-version: 1.1.0 message: "If you use this software, please cite it as below." authors: - family-names: Mangham given-names: Sam orcid: https://orcid.org/0000-0001-7511-5652 - family-names: Crouch given-names: Steven orcid: https://orcid.org/0000-0001-8985-6814 title: Climate Analysis Code version: 1.1 doi: 10.5072/zenodo.896790 date-released: 2021-08-26git add CITATION.cff git commit -m "Added citation instructions"[master 88ed80d] Added citation instructions 1 file changed, 13 insertions(+) create mode 100644 CITATION.cffgit pushEnumerating objects: 4, done. Counting objects: 100% (4/4), done. Delta compression using up to 4 threads Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 510 bytes | 510.00 KiB/s, done. Total 3 (delta 1), reused 0 (delta 0), pack-reused 0 remote: Resolving deltas: 100% (1/1), completed with 1 local object. To github.com:smangham/climate-analysis.git d596ad4..88ed80d master -> masterNow, when we check on GitHub, there’s a button that provides a BibTex (or APA) format citation for your code.
Software licensing
Software licensing can be a whole topic in itself, so we’ll just summarise here. Your institution’s Intellectual Property (IP) team will be able to offer specific guidance that fits the way your institution thinks about software.
In IP law, software is considered a creative work of literature, so any code you write automatically has copyright protection applied. This copyright will usually belong to the institution that employs you, but this may be different for PhD students. If you need to check, this should be included in your employment / studentship contract or talk to your university’s IP team.
Since software is automatically under copyright, without a license no one may:
- copy it
- distribute it
- modify it
- extend it
- use it (unclear - this has not been properly tested in court yet)
Fundamentally there are two kinds of license, Open Source licenses and Proprietary licenses, which serve slightly different purposes.
Proprietary licenses are designed to pass on limited rights to end users, and are most suitable if you want to commercialise your software. They tend to be customised to suit the requirements of the software and the institution to which it belongs - again your institutions IP team will be able to help here.
Open Source licenses are designed more to protect the rights of end users - they specifically grant permission to make modifications and redistribute the software to others. The website Choose A License provides recommendations and a simple summary of some of the most common open source licenses.
Within the open source licenses, there are two categories, copyleft and permissive. The permissive licenses such as MIT and the multiple variants of the BSD license are designed to give maximum freedom to the end users of software. These licenses allow the end user to do almost anything with the source code.
The copyleft licences in the GPL still give a lot of freedom to the end users, but any code that they write based on GPLed code must also be licensed under the same license. This gives the developer assurance that anyone building on their code is also contributing back to the community. It’s actually a little more complicated than this, and the variants all have slightly different conditions and applicability, but this is the core of the license.
Which of these types of license you prefer is up to you and those you develop code with. If you want more information, or help choosing a license, the Choose An Open-Source License (linked here) site can help.
Key Points
Releases are stable versions of the code.
Zenodo can automatically generate DOIs for releases.
Software licenses can restrict what others can do with your code.
Writing Sustainable Code
Overview
Teaching: 20 min
Exercises: 5 minQuestions
How do I write code to make future development easier?
Objectives
Understand the benefits of making your code more readable.
Rename variables and functions to be more descriptive.
Understand how to use comments to describe the code.
Use docstrings to describe the inputs and outputs of functions.
Now we’ve covered the process around developing and releasing our software. However, one key part of software development we haven’t touched on yet is the code itself. No matter how well we manage our development, if we don’t write sustainable code, then our project will suffer.
One major problem in software development is technical debt- a term for when decisions made early-on in the project (often made on the fly without much thought) end up causing long-term problems, and require a major expenditure of effort to fix (or to pay off the technical debt). If you accrue too much technical debt without fixing it, the whole project can become unsustainable, and the effort required to fix them becomes so large you have to throw the project away and start from scratch.
So when developing academic software, we need to make sure it’s sustainable. One of the key factors for this is keeping your code readable and maintainable. We want to minimise the amount of effort required for you (or others) to read your code, understand what’s going on, and make changes to it.
In this episode, we’re going to use python as an example language. The kind of principles we discuss will be applicable to any language!
Naming Things
Good names are one of the key requirements to make a code easy to maintain. Take a look at the two lines of code below:
out(p(f(v), 2) + 1)
print(process(fibonacci(argument), 2) + 1)
Which one of the two is easiest to read and understand? It’s much easier to upkeep a code where what happens on each line is clear on that line, without having to read comments describing what each variable actually is. When you have to go back to a function you wrote in a hurry six months ago to figure out where the bug is, you’d definitely prefer it was written like the latter.
There’s some common naming recommendations:
- Variables are usually lower case (e.g. speed, participant_age)
- Classes are typically capitalised nouns (e.g. Molecule, BlackHole, DNASequence)
- Functions are typically verbs (e.g. splice_gene_sequence, calculateOrbit)
Whilst these names are a lot longer than a or val_x, text editors like Visual Studio Code offers code completion. You can start typing p and be prompted with your variable patient_id. Not only does this mean it’s no more difficult to write easily-maintainable code, it also helps avoid you making typos! If your variables are f, g and v, a single mispressed key can cause you a world of trouble.
Naming Styles
There’s two main styles of naming multi-word variables, camelCase and snake_case. Some languages have common standards which recommend which to use, but in general it’s good to be consistent whichever you pick!
Python recommends capitalised CamelCase for classes, lower-case snake_case() for functions and variables, and upper-case SNAKE_CASE for constants.
Single-Character Names
You might think that some single-character names are perfectly clear- for example,
Cobviously refers to the speed of light! Unfortunately, not everyone will agree. Any mathematical libraries you use are likely to have their own interpretation of what each letter should stand for that are likely to be at odds with your field’s definitions. If so, this can lead to some very inconvenient errors to debug.In general, it’s best to give everything a name at least three characters long. You might use a prefix, e.g.
CONST_Cfor ‘constant’, or a more verbose description, e.g.V_LIGHT.
Documenting your Code
If your code has descriptive variables and function names, then it should go a long way towards making it clear what it does. But unfortunately, codes of any real size rapidly become too complicated to understand just by reading the code! Even if your code doesn’t start that large, it will almost certainly end up that way. So it’s a good idea to write clear documentation from the start, to make sure you don’t have to go back and do it later.
Comments
If you’ve used clear variable names, then the actual logic and processes of the code should be readable from the text. So with comments, we can describe things in more detail- explaining what’s going on at a high level, so you don’t have to read an entire function to understand what it does.
In Python, you can comment your code by starting a line with a #:
def fahr_to_cels(fahr):
# Convert temperature in Fahrenheit to Celsius
cels = (fahr + 32) * (5 / 9)
return cels
You can also add these at the end of lines, e.g.:
def fahr_to_cels(fahr):
cels = (fahr + 32) * (5 / 9) # Convert temperature in Fahrenheit to Celsius
return cels
A good rule of thumb is to assume that someone will always read your code at a later date, and this includes a future version of yourself. It can be easy to forget why you did something a particular way in six months time.
They should be able to understand a single function or method from its code and its comments, and shouldn’t have to look elsewhere in the code for clarification. It can be easy to get lost in code, and others will not have the same knowledge of our project or code as we do.
The kind of things that need to be commented are:
- Why certain design or implementation decisions were adopted, especially in cases where the decision may seem counter-intuitive
- The names of any particular equations you’ve implemented or algorithms you’ve used
- The format of input or output files the code uses
There are some restrictions. Comments that simply restate what the code does are redundant, and comments have to be accurate, as an incorrect comment is more confusing than no comment at all.
Docstrings
For your functions, it can be incredibly helpful to have this documentation on what they do in a structured way. The key properties of a function are what it does, what arguments it takes, and what values it returns. If you have this information everywhere, then when you’re scanning through the code and come across a function, you can just hop over and check out the summary and you’ll know exactly what’s going on.
We’re going to look at an example of how to do this in Python. If the first thing in a function is a string that isn’t assigned to a variable, that string is attached to the function as its documentation. Take a look at the example in this function for calculating Fibonacci numbers:
def fibonacci(n):
"""
Calculate the Fibonacci number of the given integer.
A recursive implementation of Fibonacci.
:param n: integer
:raises ValueError: raised if n is less than zero
:returns: fibonacci number, integer
"""
if n < 0:
raise ValueError('Fibonacci is not defined for N < 0')
if n == 0:
return 0
if n == 1:
return 1
return fibonacci(n - 1) + fibonacci(n - 2)
This documentation lists the input variables, what the function returns, and any errors it might raise too. Along with a helpful description of what the function does, this information can act as a contract for readers to understand what to expect in terms of behaviour when using the function, as well as how to use it.
This kind of clear, firm description of a function provides a solid basis for future devlopment. If you write a function that can only take positive numbers, but don’t document that, then someone else might try and feed it negative numbers without realising that’s not possible. Then, they’ll be faced with a crash at best, or at worst the code will quietly give them the wrong answer.
These types of comments are called docstrings in Python. We don’t need to use triple quotes when we write one, but if we do, we can break the string across multiple lines.
You can also write docstrings for entire Python modules- the community standard PEP 257 suggests each Python module should have a brief description, and then list the classes and functions within it. So at the beginning of a file we can just add a docstring explaining what is it, and what it contains. For example, if fibonacci() was included in a module with other functions, our module could have at the start of it:
"""
A module for generating numerical sequences of numbers that occur in nature.
Functions:
fibonacci - returns the Fibonacci number for a given integer
golden_ratio - returns the golden ratio number to a given Fibonacci iteration
...
"""
...
There’s a number of different docstring formats:
- reST - based on reStructuredText, is the most common at the moment
- Epytext - historically based on a format of docstrings used for Java, in their javadoc documentation
- Google - they have their own format
- numpydoc - recommended by Numpy, based on the Google format, quite verbose
The format we’re using here for our examples is reST. The various formats differ in terms of how they format things like parameters and output values.
Not only does having well-structured docstrings (or their equivalents in another language) make development easier for you, if you stick to an existing format for them then they can be machine-readable too. That allows sites (like ReadTheDocs (linked here)) to compile your code comments into a searchable website. You can even hyperlink between functions, or use add-ons to include LaTeX equations into the site (look at the Dask Documentation (linked here) for an example of a large, sophisticated site built by ReadTheDocs).
Improved Commenting for our Temperature Functions
Let’s think about some example functions:
def fahr_to_cels(fahr): # Convert temperature in Fahrenheit to Celsius cels = (fahr + 32) * (5 / 9) return cels def fahr_to_kelv(fahr): # Convert temperature in Fahrenheit to Kelvin cels = fahr_to_cels(fahr) kelv = cels + 273.15 return kelvOpen up Visual Studio Code and create a new file called
temperature_conversion.py, then paste the example functions in and save it. Then turn each of the comments into Python docstrings that explain briefly what the function does, its arguments, and what the function returns. Finally, add a docstring to the top of the file that describes it.Solution
""" A module for converting temperatures between imperial and metric. Functions: fahr_to_celcius - Converts a float temperature in Fahrenheit to Celcius fahr_to_kelvin - Converts a float temperature in Fahrenheit to Kelvin """ def fahr_to_celsius(fahr): """ Convert Fahrenheit to Celsius. Uses standard Fahrenheit to Celsius formula. :param fahr: float temperature in Fahrenheit :returns: float temperature in Celsius """ celsius = ((fahr - 32) * (5/9)) return celsius def fahr_to_kelvin(fahr): """ Convert Fahrenheit to Kelvin. Uses standard Fahrenheit to Kelvin formula, making use of fahr_to_celsius function. :param fahr: float temperature in Fahrenheit :returns: float temperature in Kelvin """ kelvin = fahr_to_celsius(fahr) + 273.15 return kelvin
Help
For languages like Python, docstrings are useful as they’re what’s displayed when you use
helpto get more information about a function.If you have Python installed, you can test this by opening up a terminal wherever you saved the
temperature_conversion.pyfile, and trying:from temperature_conversion import fahr_to_celcius help(fahr_to_celcius)
Key Points
Always assume that someone else will read your code at a later date, including yourself.
Rename variables and functions to add context to make your code more readable.
Add comments to explain why something was done in a certain way if not obvious.
Don’t add comments that just restate what code clearly already does.
Use docstrings contained within
"""at the start of functions and files to explain their behaviour and input/output parameters.
Managing a Mini-Project
Overview
Teaching: 0 min
Exercises: 20 minQuestions
How do we put everything we’ve learnt together?
Objectives
Go through the steps of managing a small software project.
Now we’ve seen all the steps involved in developing sustainable code, let’s put that knowledge into practise.
Identifying issues
Earlier, we made a fork of the
rf4repository. The code there is pretty bad- it’s written in a very unsustainable way that makes future development harder (and passing the project on to another researcher even harder!). However, as a published project owned by somebody else, we don’t have the permissions required to edit it and fix the problems.Fortunately, we have already forked it, and now we’re going to set up a small project to improve it. Take a look at your fork of the
rf4repository, identify three problems with the code, and raise them as issues. Forks don’t have Issues by default, but you can enable them using Settings -> Options -> Features.Don’t try to run the code- there’s more than enough things wrong with it that you can spot just from a quick read-through.
Once you’ve got your issues, create a kanban board on the repo and place them on it.
Solution
There’s too many things wrong to provide an exhaustive list, but here’s a few you may have spotted:
- No stable releases
- No development branch
- Unclear commit messages
LICENSE.mdis emptyREADME.mdhas an inaccurate list of filesREADME.mdcontains broken linksWhat questions do we want to answer with this data?is unfinished- Multiple versions of the same file in the repository
- Poorly-named functions (e.g.
add_column5)- Poorly-named variables (e.g.
df47)- Poorly-documented functions *(e.g.
plot_bar_charts)- Undocumented functions (e.g.
produce_count)
Solving problems
Now we’ve got a project board with all our problems in the To Do column, we can set about fixing one of the issues.
We want to use the feature-branch workflow, so it would be easy to collaborate with other people. Pick one of your open issues, and fix it using the feature-branch workflow, then once it’s done issue a release of your updated
masterbranch!Solution
In order to address the issue we chose, we’ll need to do the following:
- Move our issue from To Do to Work In Progress
- Select our
masterbranch, and create adevbranch coming off it- Select our
devbranch, and create a new issue branch coming off it- you could call itissue_<problem_description>or similar- Switch to our issue branch, fix the issue, commit our fixes and push them
- Submit a pull request from our issue branch to
dev- Close our issue on GitHub
- When
devis up to date, submit a pull request fromdevtomaster- When
masteris up to date, issue a release on GitHubNormally, we wouldn’t just merge a branch into
devthendevstraight intomaster- we’d merge several fixes or new features intodev, then merge tomasterand make a release.
Now you should have a good idea of the skills and techniques required to manage a project successfully!
Key Points
Problems with code and documentation can be tracked as issues.
Issues can be managed on a project board.
Issues can be fixed using the feature-branch workflow.
Stable versions of the code can be published as releases.