Python Basics
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Introduction to running the Python interpreter
- Introduction to Python variables
- Creating and Assigning values to variables
Running the Python interpreter
Normally, you write Python programs in a Python script, which is basically a file of Python commands you can run. But to start with, we’ll take a look at the Python interpreter. It’s similar to the shell in how it works, in that you type in commands and it gives you results back, but instead you use the Python language.
It’s a really quick and convenient way to get started with Python, particularly when learning about things like how to use variables, and it’s good for playing around with what you can do and quickly testing small things. But as you progress to more interesting and complex things you need to move over to writing proper Python scripts, which we’ll see later.
You start the Python interpreter from the shell by:
$ python
And then you are presented with something like:
Python 3.4.3 |Anaconda 2.3.0 (x86_64)| (default, Mar 6 2015, 12:07:41)
[GCC 4.2.1 (Apple Inc. build 5577)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
And lo and behold! You are presented with yet another prompt. So, we’re actually running a Python interpreter from the shell - it’s only yet another program we can run from the shell after all. But shell commands won’t work again until we exit the interpreter.
You can exit the interpreter and get back to the shell by typing:
>>> exit()
…or alternatively pressing the Control and D keys at the same time. Then you’ll see:
$
Phew - back to the shell!
But let’s get back to the Python interpreter and learn about variables in Python:
$ python
And we’re back to the Python interpreter:
Python 3.4.3 |Anaconda 2.3.0 (x86_64)| (default, Mar 6 2015, 12:07:41)
[GCC 4.2.1 (Apple Inc. build 5577)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
Variables
A variable is just a name for a value,
such as x, current_temperature, or subject_id.
Python’s variables must begin with a letter.
A variable in Python is defined through assignment i.e. we can create a new variable simply by assigning a value to it using =.
As an illustration,
consider the simplest collection of data,
a single value.
The line below assigns a value to a variable:
weight_kg = 55
Once a variable has a value, we can print it:
print(weight_kg)
55
and do arithmetic with it:
print('weight in pounds:', 2.2 * weight_kg)
weight in pounds: 121.0
In the above example, a floating point number 55 object has a tag labelled weight_kg.
If we reassign to weight_kg, we just move the tag to another object as shown below.
We can change a variable’s value by assigning it a new one:
weight_kg = 57.5
print('weight in kilograms is now:', weight_kg)
weight in kilograms is now: 57.5
Now the name weight_kg is attached to another floating point number 57.5 object.
Hence, in Python, a name or identifier or variable is like a name tag attached to an object.
Python has names and everything is an object.
As the example above shows, we can print several things at once by separating them with commas.
If we imagine the variable as a sticky note with a name written on it, assignment is like putting the sticky note on a particular value:

This means that assigning a value to one variable does not change the values of other variables. For example, let’s store the subject’s weight in pounds in a variable:
weight_lb = 2.2 * weight_kg
print('weight in kilograms:', weight_kg, 'and in pounds:', weight_lb)
weight in kilograms: 57.5 and in pounds: 126.5

and then change weight_kg:
weight_kg = 100.0
print('weight in kilograms is now:', weight_kg, 'and weight in pounds is still:', weight_lb)
weight in kilograms is now: 100.0 and weight in pounds is still: 126.5

Since weight_lb doesn’t remember where its value came from,
it isn’t automatically updated when weight_kg changes.
This is different from the way spreadsheets work.
Although we commonly refer to variables even in Python (because it is the common terminology), we really mean names or identifiers. In Python, variables are name tags for values, not labelled boxes.
What’s inside the box?
Draw diagrams showing what variables refer to what values after each statement in the following program:
weight = 70.5 age = 35 # Take a trip to the planet Neptune weight = weight * 1.14 age = age + 20
Sorting out references
What does the following program print out?
first, second = 'Grace', 'Hopper'first = Grace second = Hopperthird, fourth = second, first print(third, fourth)
Key Points
Arrays, Lists etc
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Lists and Arrays in Python
- Indexing and slicing
Arrays in Python
So we can use variables to hold values which we can then manipulate - useful! But what about when we need to hold many different values, such as a set of phone numbers?
One of the most fundamental data structures in any language is the array, used to hold many values at once. Python doesn’t have a native array data structure, but it has the list which is much more general and can be used as a multidimensional array quite easily.
List basics
A list in python is just an ordered collection of items which can be of any type. By comparison an array is an ordered collection of items of a single type - so a list is more flexible than an array.
We can also add and delete elements from a Python list at any time - Python lists are what is known as a dynamic and mutable type.
Lists are built into the language (so we don’t have to load a library to use them).
To define a list we simply write a comma separated list of items in square brackets:
odds = [1, 3, 5, 7, 9, 11, 15]
print('Odds are:', odds)
Odds are: [1, 3, 5, 7, 9, 11, 15]
This looks like an array because we can use indexing to pick out an individual element - indexes start from 0.
Programming languages like Fortran and MATLAB start counting at 1, because that’s what human beings have done for thousands of years. Languages in the C family (including C++, Java, Perl, and Python) count from 0 because that’s simpler for computers to do.
It takes a bit of getting used to, but one way to remember the rule is that the index is how many steps we have to take from the start to get the item we want.
We select individual elements from lists by indexing them:
print('first and last:', odds[0], odds[-1])
Which will print first and last elements, i.e. value 1 and 15 in this case.
first and last: 1 15
See slide Indexing a List Example I.
Similarly to change the seventh element we can assign directly to it:
odds[6] = 13
See slide Indexing a List Example II.
Slicing
The Slicing notation looks like array indexing but it is a lot more flexible. For example:
odds[2:5]
[5, 7, 9]
See slide Slicing a List Example I.
is a sublist from the third element to the fifth i.e. from odds[2] to odds[4]. Notice that the
final element specified i.e. [5] is not included in the slice.
Also notice that you can leave out either of the start and end indexes and they will be assumed to have their maximum possible value. For example:
odds[5:]
[11, 13]
is the list from odds[5] to the end of the list and
odds[:5]
[1, 3, 5, 7, 9]
is the list up to and not including odds[5] and
odds[:]
[1, 3, 5, 7, 9, 11, 13]
is the entire list.
Slicing strings
A section of an array is called a slice. We can take slices of character strings as well:
element = 'oxygen'
print('first three characters:', element[0:3])
print('last three characters:', element[3:6])
See slide Slicing a List Example II.
first three characters: oxy
last three characters: gen
Slicing strings
What is the value of
element[:4]? What aboutelement[4:]? Orelement[:]?What is
element[-1]? What iselement[-2]? Given those answers, explain whatelement[1:-1]does.
List slicing is more or less the same as string slicing except that we can modify a slice. For example:
odds[0:2]=[17,19]
has the same effect as
odds[0]=17
odds[1]=19
NOTE:
Finally it is worth knowing that the list we assign to a slice doesn’t have to be the same size as the slice - it simply replaces it even if it is a different size.
Thin slices
The expression element[3:3] produces an empty string,
i.e., a string that contains no characters.
Lists and Strings
There is one important difference between lists and strings: we can change the values in a list, but we cannot change the characters in a string. For example:
names = ['Newton', 'Darwing', 'Turing'] # typo in Darwin's name
print('names is originally:', names)
names[1] = 'Darwin' # correct the name
print('final value of names:', names)
names is originally: ['Newton', 'Darwing', 'Turing']
final value of names: ['Newton', 'Darwin', 'Turing']
works, but:
name = 'Bell'
name[0] = 'b'
>>> name[0]='b'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
does not.
Ch-Ch-Ch-Changes
Data which can be modified in place is called mutable, while data which cannot be modified is called immutable. Strings and numbers are immutable. This does not mean that variables with string or number values are constants, but when we want to change the value of a string or number variable, we can only replace the old value with a completely new value.
Lists and arrays, on the other hand, are mutable: we can modify them after they have been created. We can change individual elements, append new elements, or reorder the whole list. For some operations, like sorting, we can choose whether to use a function that modifies the data in place or a function that returns a modified copy and leaves the original unchanged.
Be careful when modifying data in place. If two variables refer to the same list, and you modify the list value, it will change for both variables! If you want variables with mutable values to be independent, you must make a copy of the value when you assign it.
Because of pitfalls like this, code which modifies data in place can be more difficult to understand. However, it is often far more efficient to modify a large data structure in place than to create a modified copy for every small change. You should consider both of these aspects when writing your code.
There are many ways to change the contents of lists besides assigning new values to individual elements:
odds.append(21)
print('odds after adding a value:', odds)
odds after adding a value: [17, 19, 5, 7, 9, 11, 13, 15, 21]
del odds[0]
print('odds after removing the first element:', odds)
odds after removing the first element: [19, 5, 7, 9, 11, 13, 15, 21]
odds.reverse()
print('odds after reversing:', odds)
odds after reversing: [21, 15, 13, 11, 9, 7, 5, 19]
While modifying in place, it is useful to remember that python treats lists in a slightly counterintuitive way.
If we make a list and (attempt to) copy it then modify in place, we can cause all sorts of trouble:
odds = [1, 3, 5, 7]
primes = odds
primes += [2]
print('primes:', primes)
print('odds:', odds)
primes: [1, 3, 5, 7, 2]
odds: [1, 3, 5, 7, 2]
This is because python stores a list in memory, and then can use multiple names to refer to the same list. If all we want to do is copy a (simple) list, we can use the list() command, so we do not modify a list we did not mean to:
odds = [1, 3, 5, 7]
primes = list(odds)
primes += [2]
print('primes:', primes)
print('odds:', odds)
primes: [1, 3, 5, 7, 2]
odds: [1, 3, 5, 7]
This is different from how variables worked in lesson 1, and more similar to how a spreadsheet works.
Basic array operations
So far so good, and it looks as if using a list is as easy as using an array.
Where things start to go wrong just a little is when we attempt to push the similarities between lists and arrays one step too far. For example, suppose we want to create an array initialised to a particular value. Following the general array idiom in most languages we might initialise the elements to a value, say, 1. e.g.:
myList=[]
myList[1]=1
myList[2]=1
...
only to discover that this doesn’t work because we can’t assign to a list element that doesn’t already exist.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list assignment index out of range
One solution is to use the append method to add elements one by one:
myList=[]
myList.append(1)
myList.append(1)
...
This works but it only works if we need to build up the list in this particular order - which most of the time you want to do anyway.
Slicing From the End
Use slicing to access only the last four characters of a string or entries of a list.
string_for_slicing = "Observation date: 02-Feb-2013" list_for_slicing = [["fluorine", "F"], ["chlorine", "Cl"], ["bromine", "Br"], ["iodine", "I"], ["astatine", "At"]]"2013" [["chlorine", "Cl"], ["bromine", "Br"], ["iodine", "I"], ["astatine", "At"]]Would your solution work regardless of whether you knew beforehand the length of the string or list (e.g. if you wanted to apply the solution to a set of lists of different lengths)? If not, try to change your approach to make it more robust.
Solution
Use negative indices to count elements from the end of a container (such as list or string):
string_for_slicing[-4:] list_for_slicing[-4:]
Overloading
+usually means addition, but when used on strings or lists, it means “concatenate”. Given that, what do you think the multiplication operator*does on lists? In particular, what will be the output of the following code?counts = [2, 4, 6, 8, 10] repeats = counts * 2 print(repeats)
[2, 4, 6, 8, 10, 2, 4, 6, 8, 10][4, 8, 12, 16, 20][[2, 4, 6, 8, 10],[2, 4, 6, 8, 10]][2, 4, 6, 8, 10, 4, 8, 12, 16, 20]The technical term for this is operator overloading: a single operator, like
+or*, can do different things depending on what it’s applied to.Solution
The multiplication operator
*used on a list replicates elements of the list and concatenates them together:[2, 4, 6, 8, 10, 2, 4, 6, 8, 10]It’s equivalent to:
counts + countsSo using
*on lists works in a similar way as it does on strings. Where Python employs overloading, it tries to be consistent!
Key Points
Repeating actions using loops
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Write for loops to repeat simple calculations.
- Build a basic Python script and run it.
- Track changes to a loop variable as the loop runs.
- Track changes to other variables as they are updated by a for loop.
- Write as basic Python script that uses loops
Using loops to repeat things
Using the tools we’ve covered till now, repeating a simple statement many times is tedious. The only item we can currently repeat easily is printing the exact same message multiple times. For example,
print("I love programming in Python!\n"*10)
will produce the output:
I love programming in Python!
I love programming in Python!
I love programming in Python!
I love programming in Python!
I love programming in Python!
I love programming in Python!
I love programming in Python!
I love programming in Python!
I love programming in Python!
I love programming in Python!
Imagine that we wanted to number this list so that we printed:
1. I love programming in Python!
2. I love programming in Python!
3. I love programming in Python!
4. I love programming in Python!
5. I love programming in Python!
6. I love programming in Python!
7. I love programming in Python!
8. I love programming in Python!
9. I love programming in Python!
10. I love programming in Python!
Now, the times operator * is no longer capable of allowing us to produce this output. Fortunately,
Python provides us with multiple general tools for repetition where we’ll simply specify which statements
we want to be repeated and a way to determine how many times to repeat those statements.
To do that, we’ll have to teach the computer how to repeat things.
Shortcomings of the interpreter
Until now, we’ve been writing everything directly in the Python interpreter. It’s good for testing small bits of code, and you can write any Python using the interpreter - but you wouldn’t want to! Generally you want to have the option of easily running your Python code later, and you don’t want to be retyping all the code or copying and pasting it back in to the interpreter. That would be rubbish.
So, much like what we did with Bash, let’s take a look at writing a Python script that stores Python in a file that we can run at our leisure.
Programs or scripts?
The Python Software Foundation refers to Python as a ‘programming language’, But the Python documentation, us, and many others, refer to Python programs as ‘scripts’. So is Python a scripting language or a programming language? The answer is YES.
Traditionally, languages are either interpreted (like Bash) or compiled (like C). The former type were scripting languages, and the latter were programming languages. But more recently, the lines are beginning to blur.
Python can be both! You can compile Python, but you don’t need to. In addition, Python can fulfil the role of a scripting language in similar ways to Bash, including that it’s source code can be run on a multitude of supporting platforms without needing to be explicitly compiled. But it can also go much further, and it’s designed so you can pretty much write anything with it.
For that reason, it’s considered a programming language, but to add to the confusion, we refer to Python programs generally as scripts!
Our first Python script!
Suppose we want to print each character in the word “lead” on a line of its own.
One way is to use four print statements.
Let’s write a simple Python program, using our text editor, like we did
with Bash. Let’s start our text editor and type the following, saving it in a file called word_print.py:
word = 'lead'
print(word[0])
print(word[1])
print(word[2])
print(word[3])
Notice the file has .py at the end - this is a convention that indicates this
is a Python script.
Once you’ve saved it, we can run it from the command line like this (from another terminal or shell, so we can see both the program and how it runs at once):
$ python word_print.py
Here we are asking Python to run our Python script. We should see the following:
l
e
a
d
But looking at our code again, that’s a bad approach for two reasons:
-
It doesn’t scale: if we want to print the characters in a string that’s hundreds of letters long, we’d be better off just typing them in.
-
It’s fragile: if we give it a longer string, it only prints part of the data, and if we give it a shorter one, it produces an error because we’re asking for characters that don’t exist.
We can easily demonstrate the second point by changing our script to the following (just changing the first statement):
word = 'tin'
print(word[0])
print(word[1])
print(word[2])
print(word[3])
Running it again…
$ python word_print.py
…gives us the following:
t
i
n
Traceback (most recent call last):
File "loop_test.py", line 6, in <module>
print(word[3])
IndexError: string index out of range
Here’s a better approach:
word = 'lead'
for char in word:
print(char)
l
e
a
d
This is shorter—certainly shorter than something that prints every character in a hundred-letter string—and more robust as well:
word = 'oxygen'
for char in word:
print(char)
o
x
y
g
e
n
The improved version of code for printing characters uses a for loop to repeat an operation—in this case, printing—once for each thing in a collection. The general form of a loop is:
for variable in collection:
do things with variable
We can call the loop variable anything we like, but there must be a colon at the end of the line starting the loop, and we must indent the body of the loop. Unlike many other languages, there is no command to end a loop (e.g. end for); what is indented after the for statement belongs to the loop.
The great thing about Python is that the simplicity of how it handles loops means we can use the same loop structure for handling other types of data, like lists instead. So with one minor alteration:
word = ['oxygen', 'lead', 'tin']
for char in word:
print(char)
oxygen
lead
tin
Which is really helpful, and means we don’t need to remember a different way to do something else for a loop. Although, our variable names are now a bit misleading!
What’s in a name?
Whilst we can name variables anything we like, it’s a good idea to ensure the name helps you to understand what is going on. Calling our
charloop variable earlierxmay still be clear in that small script, but if our loop were quite large (and/or more complex, with other similarly named variables) it would become difficult to understand. So pick something that’s meaningful to help others, and yourself at a later date, understand what is happening.
So what’s happening in a loop?
Let’s look at a different program called count_vowels.py, with another loop that repeatedly updates a variable:
length = 0
for vowel in 'aeiou':
length = length + 1
print('There are', length, 'vowels')
$ python count_vowels.py
There are 5 vowels
It’s worth tracing the execution of this little program step by step.
Since there are five characters in 'aeiou',
the statement on line 3 will be executed five times.
The first time around, length is zero (the value assigned to it on line 1)
and vowel is 'a'.
The statement adds 1 to the old value of length,
producing 1, and updates length to refer to that new value.
The next time around,
vowel is 'e' and length is 1,
so length is updated to be 2.
After three more updates,
length is 5;
since there is nothing left in 'aeiou' for Python to process,
the loop finishes
and the print statement on line 4 tells us our final answer.
Note that a loop variable is just a variable that’s being used to record progress in a loop. It still exists after the loop is over, and we can re-use variables previously defined as loop variables as well:
length = 0
for vowel in 'aeiou':
length = length + 1
print('There are', length, 'vowels')
print('The last vowel counted was', vowel)
There are 5 vowels
The last vowel counted was u
Note also that finding the length of a string is such a common operation
that Python actually has a built-in function to do it called len, which
we can add to the end of our program:
print(len('aeiou'))
5
len is much faster than any function we could write ourselves,
and much easier to read than a two-line loop;
it will also give us the length of many other things that we haven’t met yet,
so we should always use it when we can.
From 1 to N
Python has a built-in function called
rangethat creates a list of numbers:range(3)produces[0, 1, 2](thus starting at0if only one parameter is supplied), whilstrange(2, 5)produces[2, 3, 4]. By default,rangeincrements the number by one each time. If we specify three parameters, e.g.range(3, 10, 3), the third parameter indicates how much to increase the number by each time, so we get[3, 6, 9]. Usingrange, write a loop to print the first 3 natural numbers:1 2 3Solution
for i in range(1, 4): print(i)
Turn a String Into a List
Use a for-loop to convert the string “hello” into a list of letters:
["h", "e", "l", "l", "o"]Hint: You can create an empty list like this:
my_list = []Solution
my_list = [] for char in "hello": my_list.append(char) print(my_list)
Computing powers with loops
Exponentiation is built into Python:
print(5 ** 3) 125Write a loop that calculates the same result as
5 ** 3using multiplication (and without exponentiation).
Reverse a string
Write a loop that takes a string, and produces a new string with the characters in reverse order, so
NewtonbecomesnotweN.
Key Points
Processing data files
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Write a script to open a data file and print out its contents.
- Perform some operations on strings to extract desired data from it.
- Understand the basics of how Python handles objects.
- Understand good practices of how and when to write a code comment.
So far we’ve seen how to use and manipulate variables, and how to use loops in a script to process strings. But let’s take a look at a more interesting use case - performing some temperature conversions on our CSV data file.
We’ll start out by looking at how to read the data file and print its contents in a script, and then modify our script to perform some conversions and output that. Along the way, we’ll see how we can make our code more understandable to others (as well as ourselves, when we might come back to it at a later date).
Printing out the contents of a data file
We first need to be able to read in our data from the sc_climate_data_10.csv
file, and using a loop, print out each line. Let’s write another script
called climate_analysis.py, and enter the following (see climate_analysis-1.py):
climate_data = open('../data/sc_climate_data_10.csv', 'r')
for line in climate_data:
print(line)
Using open, we first specify the file we wish to open, and then include how
we want to use that file. If we wanted to open a file to write to, we would use ‘w’, but in this case, we specify r for reading.
In general, we know that a loop will iterate over a collection and set a loop
variable to be each item in that collection. When Python deals with files, it
does something quite helpful in a loop. By specifying climate_data as our collection, it reads in a single line at a time from our data file, assigning it to our line loop control variable.
We can run our code with:
$ python climate_analysis.py
And we get the following output:
# POINT_X,POINT_Y,Min_temp_Jul_F,Max_temp_jul_F,Rainfall_jul_inch
461196.8188,1198890.052,47.77,58.53,0.76
436196.8188,1191890.052,47.93,58.60,0.83
445196.8188,1168890.052,47.93,58.30,0.74
450196.8188,1144890.052,48.97,56.91,0.66
329196.8188,1034890.052,49.26,59.86,0.78
359196.8188,1017890.052,49.39,58.95,0.70
338196.8188,1011890.052,49.28,58.73,0.74
321196.8188,981890.0521,48.20,61.41,0.72
296196.8188,974890.0521,48.07,61.27,0.78
299196.8188,972890.0521,48.07,61.41,0.78
Hmmm… but that’s not really perfect, since it’s also printing out additional
newlines which exist at the end of each line in our data file.
We can remove them by stripping them out, using rstrip, a function
that works on strings. We can use it like:
print(line.rstrip())
So what’s happening here?
Python and object orientation - in a nutshell
So far we’ve used strings, which are a type of object in Python. In general, an object is an instance of something called a class.
A class defines how a certain thing can behave, and an object is then a particular thing that behaves the way its class tells it to. You can define classes that include properties (like variables, associated with that class), and methods (like functions, also associated with that class and can perform operations on them). We can use classes to define things in the real world.
For example, a car is made up of things like an engine, wheels, windows, and so forth - these things could be defined as classes. And for each of these, they would have their own properties and methods. A wheel class for example, could have diameter and width as properties, and a window could have size, tint and shape and properties, and assuming it’s an electric window, it could have up() and down() as methods to raise and lower the window. A class can have as many properties and methods as we choose to define for it.
When we define a particular car, we could say it has a single engine, four wheels and four windows. Each of these would be an object — an instance of its class — each with its own set of properties, which could all be different. We’re taking advantage of the fact that all four windows and all four wheels will behave the same way, but individually. Using the down() method on one of the windows would cause that window to lower, but only that window.
So, in our example,
lineis a String object, an instance of a String class. And that String class has a defined method calledrstrip(), which removes the trailing newline. There are many other String methods which are incredibly useful!
So, let’s try that out (see climate_analysis-2.py):
climate_data = open('../data/sc_climate_data_10.csv', 'r')
for line in climate_data:
print(line.rstrip())
And now we get:
# POINT_X,POINT_Y,Min_temp_Jul_F,Max_temp_jul_F,Rainfall_jul_inch
461196.8188,1198890.052,47.77,58.53,0.76
436196.8188,1191890.052,47.93,58.60,0.83
445196.8188,1168890.052,47.93,58.30,0.74
450196.8188,1144890.052,48.97,56.91,0.66
329196.8188,1034890.052,49.26,59.86,0.78
359196.8188,1017890.052,49.39,58.95,0.70
338196.8188,1011890.052,49.28,58.73,0.74
321196.8188,981890.0521,48.20,61.41,0.72
296196.8188,974890.0521,48.07,61.27,0.78
299196.8188,972890.0521,48.07,61.41,0.78
Much better!
Selecting and printing out only part of the data
But we’re not being very discriminating with our data, we’re just blindly printing out everything. Let’s assume we need to process the individual column that represents the maximum temperature for July, the 4th one, how do we extract it from the line of data?
As luck (or more likely, good design) would have it, there’s a handy string
method called split() which can separate all the columns into a list.
We’ve seen how we can trim trailing newlines from strings with rstrip() acting
on a string object. Well, we use split() in exactly the same way:
data = line.split(',')
Although in this case, we’re capturing the returned list from split() into a
variable called data. We can access elements in that list as before.
So, let’s change our code accordingly (see climate_analysis-3.py):
climate_data = open('../data/sc_climate_data_10.csv', 'r')
for line in climate_data:
data = line.split(',')
# print 4th column (max temperature)
print('Max temperature', data[3])
Now, it’s important to remember that the column we want, the maximum
temperature, is the 4th column. But in Python list indexes start at 0, so in
fact we need to obtain the value from data[3] and not data[4]. So, we
have made a note to that effect in a comment.
How and when should you add a comment?
The trick is to keep your audience in mind when writing code — this could be someone else in the lab, or perhaps someone in another institution. A good rule of thumb is to assume that someone will always read your code at a later date, and this includes a future version of yourself. It can be easy to forget why you did something a particular way in six months time.
Which leads to a good point about comments: generally, they should explain the why. In most cases, the code already explains the how, so if something could be considered unclear, add a comment.
A good philosophy on code comments is that the best kind of comments are the ones you don’t need. You should write your code so it’s easier to understand without comments first, and only add comments when it cannot be made easier to understand.
And we get:
Max temperature Max_temp_jul_F
Max temperature 58.53
Max temperature 58.60
Max temperature 58.30
Max temperature 56.91
Max temperature 59.86
Max temperature 58.95
Max temperature 58.73
Max temperature 61.41
Max temperature 61.27
Max temperature 61.41
This perhaps isn’t what we want - the column header is also part of the output!
Key Points
Making choices
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Write conditional statements including
if,elif, andelsebranches.- Evaluate expressions containing
andandor.- Use conditionals to conditionally process input data.
So what if we want to do something that’s dependent on whether a given condition is true? In this lesson, we’ll learn how to write code that runs only when certain conditions are true.
Conditionals
We can ask Python to take different actions, depending on a condition, with an if statement (you’ll need to type this in - don’t copy and paste this code directly, it won’t work):
num = 37
if num > 100:
print("greater")
else:
print("not greater")
print("done")
not greater
done
The second line of this code uses the keyword if to tell Python that we want to make a choice.
If the test that follows it is true,
the body of the if
(i.e., the lines indented underneath it) are executed.
If the test is false,
the body of the else is executed instead.
Only one or the other is ever executed:

Conditional statements don’t have to necessarily include an else.
If there isn’t one,
Python simply does nothing if the test is false
(you’ll need to type this in - don’t copy and paste this code directly, it won’t work):
num = 53
print("before conditional...")
if num > 100:
print("53 is greater than 100")
print("...after conditional")
before conditional...
...after conditional
We can also chain several tests together using elif,
which is short for “else if” as shown in the example code chunk below:
num = -3
if num > 0:
print("Sign of a number:",num,"is:",1)
elif num == 0:
print("Sign of a number",num,"is:",0)
else:
print("Sign of a number",num, "is:",-1)
sign of a number -3 is: -1
The keyword elif is short for else if, and is useful to avoid excessive indentation. An
if ... elif ... elif ... sequence is a substitute for the switch or case statements
found in other languages.
One important thing to notice in the code above is that we use a double equals sign == to test for equality
rather than a single equals sign
because the latter is used to mean assignment.
This convention was inherited from C,
and while many other programming languages work the same way,
it does take a bit of getting used to…
We can also combine tests using and and or.
and is only true if both parts are true:
if (1 > 0) and (-1 > 0):
print("both parts are true")
else:
print("one part is not true")
one part is not true
while or is true if either part is true:
if (1 < 0) or ('left' < 'right'):
print("at least one test is true")
at least one test is true
In this case, “either” means “either or both”, not “either one or the other but not both”.
How many paths?
Which of the following would be printed if you were to run this code? Why did you pick this answer?
- A
- B
- C
- B and C
if 4 > 5: print('A') elif 4 <= 5: print('B') elif 4 < 5: print('C')Solution
C gets printed because the first two conditions,
4 > 5and4 == 5, are not true, but4 < 5is true.
What Is Truth?
TrueandFalseare special words in Python calledbooleanswhich represent true and false statements. However, they aren’t the only values in Python that are true and false. In fact, any value can be used in aniforelif. After reading and running the code below, explain what the rule is for which values are considered true and which are considered false.if '': print('empty string is true') if 'word': print('word is true') if []: print('empty list is true') if [1, 2, 3]: print('non-empty list is true') if 0: print('zero is true') if 1: print('one is true')
Another type of loop
We’ve seen how to write loops where perhaps we know how many times we want the loop to execute beforehand, e.g. printing out each character in a string. So we can use for loops to execute a fixed operation over a known number of steps.
But what if we want our loop to continue to execute until some other condition is true?
Perhaps our code runs a simulation that generates a set of results each time through
the loop, but we’re not sure when the results will be what we want, i.e. we don’t
know how many times the loop needs to execute. For these types of cases, we can use a
while loop, which is similar to a for loop but exits the loop when some condition is
true.
Consider the following example:
from random import randint
number = 0
while number != 5:
number = randint(1, 10)
print(number)
We use Python’s ability to generate a random number here for clarity, but this could instead be calling a function that runs another step in our simulation and returns a result.
So in this case, our loop will continue to generate and print out random numbers between and 10 while the generated number is not equal to 5. When the random number generated is 5, the loop will exit.
while loops are a more general case of loops which are often useful (you can even
simulate a for loop using a while loop). But you should preferably use for loops
as opposed to while loops where you can, since they are more specific and it’s more
readable - it’s easier to figure out how many times the loop will execute.
Climate Analysis: adding a condition to avoid printing comments
We’re still getting our column header at the top of our output, and perhaps we don’t want that. We need to able to check whether the line begins with a ‘#’ (which denotes a comment line), and if so, avoid printing it out.
So let’s use an if statement to do that (see climate_analysis-4.py):
climate_data = open('../data/sc_climate_data_10.csv', 'r')
for line in climate_data:
data = line.split(',')
if data[0][0] == '#':
# don't want to process comment lines, which start with '#'
pass
else:
# print 4th column (max temperature)
print('Max temperature', data[3])
Max temperature 58.53
Max temperature 58.60
Max temperature 58.30
Max temperature 56.91
Max temperature 59.86
Max temperature 58.95
Max temperature 58.73
Max temperature 61.41
Max temperature 61.27
Max temperature 61.41
Key Points
Modularising your code using functions
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Define a function that takes parameters.
- Return a value from a function.
- Understand the scope of function variables and parameters.
- Documenting a function.
- Understand why we should divide programs into small, single-purpose functions.
- Define and use a module that contains functions.
At this point, we’ve written some scripts to do various things, including one to loop through a data file and output its contents. But it’s not hard to imagine our code getting more complicated as we add more features.
We’ll see how we can amend our code to be better structured to further increase its readability, as well as its maintainability and reuse in other applications.
Converting from Fahrenheit to Celsius
Let’s look at adding a feature to our code to perform a conversion from Fahrenheit to Celsius on the temperature data we are looking at:
celsius = ((data[3] - 32) * (5/9))
Now this wouldn’t work as it is - we can’t just apply this formula directly to
data[3] since it’s a string. We need to convert it to a number first. To be
specific, a floating point number.
Fortunately, Python has some built-in functions to do these type conversions
(see climate_analysis-5.py):
climate_data = open('../data/sc_climate_data_10.csv', 'r')
for line in climate_data:
data = line.split(',')
if data[0][0] == '#':
# don't want to process comment lines, which start with '#'
pass
else:
# extract our max temperature in Fahrenheit - 4th column
fahr = float(data[3])
# apply standard Fahrenheit to Celsius formula
celsius = ((fahr - 32) * (5/9))
print('Max temperature in Celsius', celsius)
So we first convert our data[3] value to a floating point number using
float(), then we are free to use it in our conversion formula. Depending on
the structure of your own data, you may find you end up doing this a lot!
So now we get:
Max temperature in Celsius 14.73888888888889
Max temperature in Celsius 14.777777777777779
Max temperature in Celsius 14.61111111111111
Max temperature in Celsius 13.838888888888887
Max temperature in Celsius 15.477777777777778
Max temperature in Celsius 14.972222222222225
Max temperature in Celsius 14.85
Max temperature in Celsius 16.33888888888889
Max temperature in Celsius 16.261111111111113
Max temperature in Celsius 16.33888888888889
Modularising conversion code into a function
Whilst this is a simple calculation, there are many things we may want to do that are more complex. What is essentially a single task may require a number of lines of code to accomplish it, and with many of these our code could become quite messy. And if we’d like to reuse that code elsewhere, we’d have to copy it.
Duplicating portions of code can lead to a host of problems with modifying our code in the future, aside from making the code more lengthy and unreadable. We’d have to update all our copies if we wanted to update how we accomplished that task, which can introduce errors. And if errors already exist in our original code, we would have to correct all copies, which would become a code maintenance nightmare.
We’d ideally like a way to package our code succinctly, so we only need to change it in one place, and so that it is easier to reuse. Python provides for this by letting us define things called ‘functions’ - a shorthand way of re-executing pieces of code.
So going back to our climate code, we can modularise our temperature
conversion code into a function (see climate_analysis-6.py):
climate_data = open('../data/sc_climate_data_10.csv', 'r')
def fahr_to_celsius(fahr):
# apply standard Fahrenheit to Celsius formula
celsius = ((fahr - 32) * (5/9))
return celsius
for line in climate_data:
data = line.split(',')
if data[0][0] == '#':
# don't want to process comment lines, which start with '#'
pass
else:
# extract our max temperature in Fahrenheit - 4th column
fahr = float(data[3])
celsius = fahr_to_celsius(fahr)
print('Max temperature in Celsius', celsius)
The definition opens with the word def,
which is followed by the name of the function
and a parenthesized list of parameter names.
The body of the function — the
statements that are executed when it runs — is indented below the definition line,
typically by four spaces.
When we call the function, the values we pass to it are assigned to those variables so that we can use them inside the function. Inside the function, we use a return statement to send a result back to whoever asked for it.
Combining Strings
“Adding” two strings produces their concatenation:
'a' + 'b'is'ab'. Write a short function calledfencethat takes two parameters calledoriginalandwrapperand returns a new string that has the wrapper character at the beginning and end of the original. A call to your function should look like this:print(fence('name', '*'))*name*Solution
def fence(original, wrapper): return wrapper + original + wrapper
How large should functions be?
We use functions to define a big task in terms of smaller ones. This helps to make our code more readable, as well as allowing us to more easily reuse and maintain that code.
The trick when writing functions is to ensure they don’t themselves become unmanageable, and it’s very easy to write large functions. So when your function starts getting large, consider decomposing it further into separate functions. There’s no hard and fast rule for when a function is too ‘large’ — some say 15-20 lines, some say no more than a page long. But in general, think about how complex it is to understand, generally how readable it is, and whether it would benefit from splitting up into more functions.
Note that the function is at the top of the script. This is because Python reads the script from top to bottom, and if we called the function before we defined it, Python wouldn’t know about it and throw an error like this:
Traceback (most recent call last):
File "climate_analysis-6.py", line 13, in <module>
celsius = fahr_to_celsius(fahr)
NameError: name 'fahr_to_celsius' is not defined
And when we run it again — which we most definitely should, to make sure it’s still working as expected — we see the same output, which is correct.
How do function parameters work?
We actually used the same variable name
fahrin our main code and and the function. But it’s important to note that even though they share the same name, they don’t refer to the same thing. This is because of variable scoping.Within a function, any variables that are created (such as parameters or other variables), only exist within the scope of the function.
For example, what would be the output from the following:
f = 0 k = 0 def multiply_by_10(f): k = f * 10 return k multiply_by_10(2) multiply_by_10(8) print(k)
- 20
- 80
- 0
Solution
3 - the f and k variables defined and used within the function do not interfere with those defined outside of the function.
This is really useful, since it means we don’t have to worry about conflicts with variable names that are defined outside of our function that may cause it to behave incorrectly. This is known as variable scoping.
Does the sum of a list equal a given value?
Write a function to take a list of numbers and another value, and return whether or not the sum of the list of numbers is equal to that value.
Following the function definition, a call to your function should look like this:
is_sum_equal([1,2,3], 6)) True is_sum_equal([2,4,6], 100) FalseSolution
def is_sum_equal(number_list, sum_value): count = 0 for number in number_list: count = count + number return count == sum_value
Performing more temperature conversions
Of course, we can also add more functions. Let’s add another, which performs a conversion from Fahrenheight to Kelvin. The formula looks like this:
kelvin = ((fahr - 32) * (5/9)) + 273.15
Now, we could just add a new function that does this exact conversion. But
Kelvin uses the same units as Celsius, the part of the formula that
converts to Celsius units is the same. We could just used our fahr_to_celsius
function for the unit conversion, and add 273.15 to that to get Kelvin. So
our new function becomes:
def fahr_to_kelvin(fahr):
# apply standard Fahrenheit to Kelvin formula
kelvin = fahr_to_celsius(fahr) + 273.15
return kelvin
Which we insert after the fahr_to_celsius function (since our new function
needs to call that one). We can then amend our code to also call that new
function and output the result. Our code then becomes (see climate_analysis-7.py):
climate_data = open('../data/sc_climate_data_10.csv', 'r')
def fahr_to_celsius(fahr):
# apply standard Fahrenheit to Celsius formula
celsius = ((fahr - 32) * (5/9))
return celsius
def fahr_to_kelvin(fahr):
# apply standard Fahrenheit to Kelvin formula
kelvin = fahr_to_celsius(fahr) + 273.15
return kelvin
for line in climate_data:
data = line.split(',')
if data[0][0] == '#':
# don't want to process comment lines, which start with '#'
pass
else:
# extract our max temperature in Fahrenheit - 4th column
fahr = float(data[3])
celsius = fahr_to_celsius(fahr)
kelvin = fahr_to_kelvin(fahr)
print('Max temperature in Celsius', celsius, 'Kelvin', kelvin)
Hmm… our code is starting to get a little large with these functions. What could we do to make it clearer and less cluttered?
Modularising conversion code into a library
Words are useful, but what’s more useful are the sentences and stories we build with them. Similarly, while a lot of powerful tools are built into languages like Python, even more live in the libraries they are used to build.
A library is a collection of code (precompiled routines, functions) that a program can use. They are particularly useful for storing frequently used routines because you don’t need to explicitly link them to every program that uses them. Libraries will be automatically looked for routines that are not found elsewhere.
So we can go one step further to improve the structure of our code. We can separate out the two functions and have them in a separate Python module (or library) which we can use.
Create a new file called
temp_conversion.py and copy and paste those two functions into it, then
save it, and remove those functions from the original climate_analysis.py
script and save that. We’ll see how to use those library functions
shortly. But first, let’s take this opportunity to improve our
documentation of those functions!
The usual way to put documentation in software is to add comments, as
we’ve already seen. But when describing functions, there’s a better way.
If the first thing in a function is a string that isn’t assigned to a variable,
that string is attached to the function as its documentation (see temp_conversion.py):
"""A library to perform temperature conversions"""
def fahr_to_celsius(fahr):
"""Convert Fahrenheit to Celsius.
Uses standard Fahrenheit to Celsius formula
Arguments:
fahr -- the temperature in Fahrenheit
"""
celsius = ((fahr - 32) * (5/9))
return celsius
def fahr_to_kelvin(fahr):
"""Convert Fahrenheight to Kelvin.
Uses standard Fahrenheit to Kelvin formula
Arguments:
fahr -- the temperature in Fahrenheit
"""
kelvin = fahr_to_celsius(fahr) + 273.15
return kelvin
A string like this is called a docstring. We don’t need to use triple quotes when we write one, but if we do, we can break the string across multiple lines. This also applies to modules
So how would we use this module and its functions in code?
We do this by importing the module into Python.
Python 3.4.3 |Anaconda 2.3.0 (x86_64)| (default, Mar 6 2015, 12:07:41)
[GCC 4.2.1 (Apple Inc. build 5577)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import temp_conversion
When modules and functions are described in docstrings, we can ask for these explanations directly from the interpreter which can be useful. Following on from the above:
>>> help(temp_conversion)
So here’s the help we get for the module:
Help on module temp_conversion:
NAME
temp_conversion - A library to perform temperature conversions
FUNCTIONS
fahr_to_celsius(fahr)
Convert Fahrenheit to Celsius.
Uses standard Fahrenheit to Celsius formula
Arguments:
fahr -- the temperature in Fahrenheit
fahr_to_kelvin(fahr)
Convert Fahrenheight to Kelvin.
Uses standard Fahrenheit to Kelvin formula
Arguments:
fahr -- the temperature in Fahrenheit
FILE
/Users/user/Projects/RSG/Training/2021-10-25-swc-python-novice/novice/python/code/temp_conversion.py
Here, note we’ve used the term library in the code documentation. This
is a more conventional, general term for a set of routines in any language.
Similarly, for Docstrings in functions, e.g.:
>>> help(temp_conversion.fahr_to_celsius)
Note that we need to put in temp_conversion. prior the function name. We need
to do this to specify that the function we want help on is within the
temp_conversion module.
So we get:
Help on function fahr_to_celsius in module temp_conversion:
fahr_to_celsius(fahr)
Convert Fahrenheit to Celsius.
Uses standard fahrenheit to Celsius formula
Arguments:
fahr -- the temperature in Fahrenheit
And then we need to import that function from our module into our script, so
we can use it (see climate_analysis-8.py).
import temp_conversion
climate_data = open('../data/sc_climate_data_10.csv', 'r')
for line in climate_data:
data = line.split(',')
if data[0][0] == '#':
# don't want to process comment lines, which start with '#'
pass
else:
# extract our max temperature in Fahrenheit - 4th column
fahr = float(data[3])
celsius = temp_conversion.fahr_to_celsius(fahr)
kelvin = temp_conversion.fahr_to_kelvin(fahr)
print('Max temperature in Celsius', celsius, 'Kelvin', kelvin)
Like when we used the interpreter to ask for help on the fahr_to_celsius()
function, we need to prefix the function with its temp_conversion module name.
Again, the results should be the same as before.
Readable Code
Revise a function you wrote for one of the previous exercises to try to make the code more readable. Then, collaborate with one of your neighbors to critique each other’s functions and discuss how your function implementations could be further improved to make them more readable.
Key Points
Handling Errors
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Be able to read and understand how Python reports errors through tracebacks
- Understand how and why errors occur in Python, and common types of errors
- Use error handling mechanisms to detect problems and respond to them
Every programmer encounters errors, both those who are just beginning, and those who have been programming for years. Encountering errors and exceptions can be very frustrating at times, and can make coding feel like a hopeless endeavour. However, understanding what the different types of errors are and when you are likely to encounter them can help a lot. Once you know why you get certain types of errors, they become much easier to fix.
Errors in Python have a very specific form, called a traceback. Let’s examine one:
print(a)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'a' is not defined
Take a look at the traceback. It shows 1 level of error, here, Name Error. The traceback shows shows the line number where the error occured and the type of error.
Variable name errors come with some of the most informative error messages, which are usually of the form “name ‘the_variable_name’ is not defined”.
Variable Name Errors
In the above example, let’s look at why does this error message occur? That’s harder question to answer, because it depends on what your code is supposed to do. However, there are a few very common reasons why you might have an undefined variable. The first is that you meant to use a string, but forgot to put quotes around it:
print(hello)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'hello' is not defined
The second is that you just forgot to create the variable before using it.
In the following example,
count should have been defined (e.g., with count = 0) before the for loop:
for number in range(10):
count = count + number
print("The count is:", count)
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
NameError: name 'count' is not defined
Finally, the third possibility is that you made a typo when you were writing your code.
Let’s say we fixed the error above by adding the line Count = 0 before the for loop.
Frustratingly, this actually does not fix the error.
Remember that variables are case-sensitive,
so the variable count is different from Count. We still get the same error, because we still have not defined count:
Count = 0
for number in range(10):
count = count + number
print("The count is:", count)
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
NameError: name 'count' is not defined
Identifying Variable Name Errors
- Read the code below (or open the file
error_name_ch.pyin code folder), and (without running it) try to identify what the errors are.- Run the code, and read the error message. What type of
NameErrordo you think this is? In other words, is it a string with no quotes, a misspelled variable, or a variable that should have been defined but was not?- Fix the error.
- Repeat steps 2 and 3, until you have fixed all the errors.
for number in range(10): # use a if the number is a multiple of 3, otherwise use b if (Number % 3) == 0: message = message + a else: message = message + "b" print(message)Solution
3
NameErrors fornumberbeing misspelled, formessagenot defined, and foranot being in quotes.Fixed version:
message = "" for number in range(10): # use a if the number is a multiple of 3, otherwise use b if (number % 3) == 0: message = message + "a" else: message = message + "b" print(message)
Syntax Errors
When you forget a colon at the end of a line,
accidentally add one space too many when indenting under an if statement,
or forget a parenthesis,
you will encounter a syntax error.
This means that Python couldn’t figure out how to read your program.
This is similar to forgetting punctuation in English:
for example,
this text is difficult to read there is no punctuation there is also no capitalization
why is this hard because you have to figure out where each sentence ends
you also have to figure out where each sentence begins
to some extent it might be ambiguous if there should be a sentence break or not
People can typically figure out what is meant by text with no punctuation, but people are much smarter than computers. If Python doesn’t know how to read the program, it will just give up and inform you with an error. For example:
def some_function()
msg = "hello, world!"
print(msg)
return msg
File "<stdin>", line 1
def some_function()
SyntaxError: invalid syntax
Here, Python tells us that there is a SyntaxError on line 1,
and even puts a little arrow in the place where there is an issue.
In this case the problem is that the function definition is missing a colon at the end.
Actually, the function above has two issues with syntax.
If we fix the problem with the colon,
we see that there is also an IndentationError,
which means that the lines in the function definition do not all have the same indentation:
def some_function():
msg = "hello, world!"
print(msg)
return msg
File "<stdin>", line 4
return msg
^
IndentationError: unexpected indent
Both SyntaxError and IndentationError indicate a problem with the syntax of your program,
but an IndentationError is more specific:
it always means that there is a problem with how your code is indented.
Tabs and Spaces
A quick note on indentation errors: they can sometimes be insidious, especially if you are mixing spaces and tabs. Because they are both whitespace, it is difficult to visually tell the difference. In the following example, where we have a file called
hello_world.py, the first two lines are using a tab for indentation, while the third line uses four spaces:def some_function(): msg = "hello, world!" print(msg) return msgFile "hello_world.py", line 4 return msg ^ TabError: inconsistent use of tabs and spaces in indentationBy default, one tab is equivalent to eight spaces, so the only way to mix tabs and spaces is to make it look like this. In general, it is better to just never use tabs and always use spaces, because it can make things very confusing.
Identifying Syntax Errors
- Read the code below (or open the file
error_syntax_ch.pyin code folder), and (without running it) try to identify what the errors are.- Run the code, and read the error message. Is it a
SyntaxErroror anIndentationError?- Fix the error.
- Repeat steps 2 and 3, until you have fixed all the errors.
def another_function print("Syntax errors are annoying.") print("But at least python tells us about them!") print("So they are usually not too hard to fix.")Solution
SyntaxErrorfor missing():at end of first line,IndentationErrorfor mismatch between second and third lines. A fixed version is:def another_function(): print("Syntax errors are annoying.") print("But at least python tells us about them!") print("So they are usually not too hard to fix.")
Index Errors
Next up are errors having to do with containers (like lists and strings) and the items within them. If you try to access an item in a list or a string that does not exist, then you will get an error. This makes sense: if you asked someone what day they would like to get coffee, and they answered “caturday”, you might be a bit annoyed. Python gets similarly annoyed if you try to ask it for an item that doesn’t exist:
letters = ['a', 'b', 'c']
print("Letter #1 is", letters[0])
print("Letter #2 is", letters[1])
print("Letter #3 is", letters[2])
print("Letter #4 is", letters[3])
Letter #1 is a
Letter #2 is b
Letter #3 is c
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
Here,
Python is telling us that there is an IndexError in our code,
meaning we tried to access a list index that did not exist.
Identifying Index Errors
- Read the code below, and (without running it) try to identify what the errors are.
- Run the code, and read the error message. What type of error is it?
- Fix the error.
seasons = ['Spring', 'Summer', 'Fall', 'Winter'] print('My favorite season is ', seasons[4])Solution
IndexError; the last entry isseasons[3], soseasons[4]doesn’t make sense. A fixed version is:seasons = ['Spring', 'Summer', 'Fall', 'Winter'] print('My favorite season is ', seasons[-1])
Here’s another example of Index Error.
# This code has an intentional error. You can type it directly or
# use it for reference to understand the error message below.
def favorite_ice_cream():
ice_creams = [
"chocolate",
"vanilla",
"strawberry"
]
print(ice_creams[3])
favorite_ice_cream()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 9, in favorite_ice_cream
IndexError: list index out of range
This particular traceback has two levels. You can determine the number of levels by looking for the number of arrows on the left hand side. In this case:
-
The first shows code from the cell above, with an arrow pointing to Line 8 (which is
favorite_ice_cream()). -
The second shows some code in the function
favorite_ice_cream, with an arrow pointing to Line 6 (which isprint(ice_creams[3])).
The last level is the actual place where the error occurred.
The other level(s) show what function the program executed to get to the next level down.
So, in this case, the program first performed a function call to the function favorite_ice_cream.
Inside this function,
the program encountered an error on Line 6, when it tried to run the code print(ice_creams[3]).
Long Tracebacks
Sometimes, you might see a traceback that is very long – sometimes they might even be 20 levels deep! This can make it seem like something horrible happened, but really it just means that your program called many functions before it ran into the error. Most of the time, you can just pay attention to the bottom-most level, which is the actual place where the error occurred.
So what error did the program actually encounter?
In the last line of the traceback,
Python helpfully tells us the category or type of error (in this case, it is an IndexError)
and a more detailed error message (in this case, it says “list index out of range”).
If you encounter an error and don’t know what it means, it is still important to read the traceback closely. That way, if you fix the error, but encounter a new one, you can tell that the error changed. Additionally, sometimes just knowing where the error occurred is enough to fix it, even if you don’t entirely understand the message.
If you do encounter an error you don’t recognize, try looking at the official documentation on errors. However, note that you may not always be able to find the error there, as it is possible to create custom errors. In that case, hopefully the custom error message is informative enough to help you figure out what went wrong.
Reading Error Messages
Read the python code (or open the file
error_index_ch.pyin code folder) and the resulting traceback below, and answer the following questions:
- How many levels does the traceback have?
- What is the function name where the error occurred?
- On which line number in this function did the error occurr?
- What is the type of error?
- What is the error message?
# This code has an intentional error. Do not type it directly; # use it for reference to understand the error message below. def print_message(day): messages = { "monday": "Hello, world!", "tuesday": "Today is tuesday!", "wednesday": "It is the middle of the week.", "thursday": "Today is Donnerstag in German!", "friday": "Last day of the week!", "saturday": "Hooray for the weekend!", "sunday": "Aw, the weekend is almost over." } print(messages[day]) def print_friday_message(): print_message("Friday") print_friday_message()Traceback (most recent call last): File "test.py", line 18, in <module> print_friday_message() File "test.py", line 16, in print_friday_message print_message("Friday") File "test.py", line 13, in print_message print(messages[day]) KeyError: 'Friday'Solution
- 3 levels
print_message- 11
KeyError- There isn’t really a message; you’re supposed to infer that
Fridayis not a key inmessages.
Silent Errors
Not all problems with our code will be revealed through explicit errors. Some defects can cause output to be incorrect, and display no error message.
Consider the following code (which you can find in normalize.py in the code directory):
def normalize_rectangle(rect):
'''Normalizes a rectangle so that it is at the origin and 1.0 units long on its longest axis.'''
x0, y0, x1, y1 = rect
dx = x1 - x0
dy = y1 - y0
if dx > dy:
scaled = float(dx) / dy
upper_x, upper_y = 1.0, scaled
else:
scaled = float(dx) / dy
upper_x, upper_y = scaled, 1.0
return (0, 0, upper_x, upper_y)
So if we normalize a rectangle that is taller than it is wide…:
from normalize import normalize_rectangle
print(normalize_rectangle( (0.0, 0.0, 1.0, 5.0) ))
…everything seems ok:
(0, 0, 0.2, 1.0)
And if we normalize one that’s wider than it is tall:
print(normalize_rectangle( (0.0, 0.0, 5.0, 1.0) ))
Everything still seems… wait a minute!
(0, 0, 1.0, 5.0)
Since the longest axis should be 1.0, we can see this is incorrect. Looking at our code, line 8 should divide dy by dx.
Debug with a Neighbour
Take a function that you have written today, and introduce a tricky bug. Your function should still run, but will give the wrong output. Switch seats with your neighbor and attempt to identify - or debug - the problem that they introduced into their function.
Not Supposed to be the Same
You are assisting a researcher with Python code that computes the Body Mass Index (BMI) of patients (open the file
error_silent_ch.pyin code folder). The researcher is concerned because all patients seemingly have identical BMIs, despite having different physiques. BMI is calculated as weight in kilograms divided by the the square of height in metres.patients = [[70, 1.8], [80, 1.9], [150, 1.7]] def calculate_bmi(weight, height): return weight / (height ** 2) for patient in patients: height, weight = patients[0] bmi = calculate_bmi(height, weight) print("Patient's BMI is: %f" % bmi)Patient's BMI is: 21.604938 Patient's BMI is: 21.604938 Patient's BMI is: 21.604938Solution
The loop is not being utilised correctly.
heightandweightare always set as the first patient’s data during each iteration of the loop.The height/weight variables are reversed in the function call to
calculate_bmi(...)
In our normalize_rectangle example, we identified and fixed the error.
But we could have missed it,
particularly if our function was doing something more complex.
So what should we do?
We should test our code as thoroughly as we can before we intend to use it,
by coming up with test cases. These tests are a set of inputs we can use to test
that our code gives the correct result, and are designed deliberately to
find faults in our code.
This means as continually add features to our code and test it, we can check
the behaviour of our code continues to be correct.
We also automate this process, and there are ways to do this, which are
beyond the scope of this course.
If you’re interested, look up unit testing in general, and for Python, you can look at Nose and PyTest which are examples of tools used to write tests in an easy to use way.
File Errors
The last type of error we’ll cover today
are those associated with reading and writing files: FileNotFoundError.
If you try to read a file that does not exist,
you will receive a FileNotFoundError telling you so.
If you attempt to write to a file that was opened read-only, Python 3
returns an UnsupportedOperationError.
More generally, problems with input and output manifest as
IOErrors or OSErrors, depending on the version of Python you use.
file_handle = open('myfile.txt', 'r')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
FileNotFoundError: [Errno 2] No such file or directory: 'myfile.txt'
One reason for receiving this error is that you specified an incorrect path to the file.
For example,
if I am currently in a folder called myproject,
and I have a file in myproject/writing/myfile.txt,
but I try to just open myfile.txt,
this will fail.
The correct path would be writing/myfile.txt.
It is also possible (like with NameError) that you just made a typo.
A related issue can occur if you use the “read” flag instead of the “write” flag.
Python will not give you an error if you try to open a file for writing when the file does not exist.
However,
if you meant to open a file for reading,
but accidentally opened it for writing,
and then try to read from it,
you will get an UnsupportedOperation error
telling you that the file was not opened for reading:
file_handle = open('myfile.txt', 'w')
file_handle.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
io.UnsupportedOperation: not readable
These are the most common errors with files, though many others exist. If you get an error that you’ve never seen before, searching the Internet for that error type often reveals common reasons why you might get that error.
Key Points
Command-Line Programs
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Use the values of command-line arguments in a program.
- Handle flags and files separately in a command-line program.
- Read data from standard input in a program so that it can be used in a pipeline.
At some point we may want to use our program in a pipeline or run it in a shell script to process thousands of data files. Our climate data is a good example - we have sample sets of 10 and 1,000 rows for development, but also a complete data file with over a million rows. We may of course want to process many more. In order to do that, we need to make our programs work like other Unix command-line tools.
Passing in the file to process as an argument
So perhaps the biggest limitation is that our script only deals with one data file, which is hardcoded into the script. Like with functions, we’d ideally want to be able to pass in the filename to process as a parameter. Then, we can run the script on any data file we like.
Fortunately, Python can handle command line arguments, which we’ve already
seen in our Bash lesson. In Python, arguments are passed
to our script in the list sys.argv[] which we can use. This feature is provided
by the Python standard sys library, so similarly to how we imported our
temperature conversion functions, we need to import the sys library.
The first argument (sys.argv[0]) always contains the name of the script,
with the arguments passed in as sys.argv[1], sys.argv[2], etc.
So we can change our script to handle a filename argument (see climate_analysis-9.py):
import sys
import temp_conversion
filename = sys.argv[1]
climate_data = open(filename, 'r')
for line in climate_data:
data = line.split(',')
if data[0][0] == '#':
# don't want to process comment lines, which start with '#'
pass
else:
# extract our max temperature in Fahrenheit - 4th column
fahr = float(data[3])
# don't process invalid temperature readings of -9999
if fahr != -9999:
celsius = temp_conversion.fahr_to_celsius(fahr)
kelvin = temp_conversion.fahr_to_kelvin(fahr)
print('Max temperature in Celsius', celsius, 'Kelvin', kelvin)
And if we run that from the shell, with
$ python climate_analysis.py ../data/sc_climate_data_10.csv
So we pass in the filename as argument that gets picked up and used. Handy! When we run it, we get the following (same as before):
Max temperature in Celsius 14.73888888888889 Kelvin 287.88888888888886
Max temperature in Celsius 14.777777777777779 Kelvin 287.92777777777775
Max temperature in Celsius 14.61111111111111 Kelvin 287.76111111111106
Max temperature in Celsius 13.838888888888887 Kelvin 286.9888888888889
Max temperature in Celsius 15.477777777777778 Kelvin 288.62777777777774
Max temperature in Celsius 14.972222222222225 Kelvin 288.1222222222222
Max temperature in Celsius 14.85 Kelvin 288.0
Max temperature in Celsius 16.33888888888889 Kelvin 289.4888888888889
Max temperature in Celsius 16.261111111111113 Kelvin 289.4111111111111
Max temperature in Celsius 16.33888888888889 Kelvin 289.4888888888889
Running our script on other data files
But now we can run it on any file, for example:
$ python climate_analysis.py ../data/sc_climate_data_1000.csv
But wait!
Max temperature in Celsius 14.73888888888889 Kelvin 287.88888888888886
Max temperature in Celsius 14.777777777777779 Kelvin 287.92777777777775
Max temperature in Celsius 14.61111111111111 Kelvin 287.76111111111106
Max temperature in Celsius 13.838888888888887 Kelvin 286.9888888888889
Max temperature in Celsius 15.477777777777778 Kelvin 288.62777777777774
Max temperature in Celsius 14.972222222222225 Kelvin 288.1222222222222
Max temperature in Celsius 14.85 Kelvin 288.0
Max temperature in Celsius 16.33888888888889 Kelvin 289.4888888888889
Max temperature in Celsius 16.261111111111113 Kelvin 289.4111111111111
Max temperature in Celsius 16.33888888888889 Kelvin 289.4888888888889
Max temperature in Celsius -5572.777777777778 Kelvin -5299.627777777779
Max temperature in Celsius 16.077777777777776 Kelvin 289.22777777777776
...
What’s this -5572.777777777778? If we look at our
sc_climate_data_1000.csv file, we can see there are some maximum
temperature values of -9999. As it turns out, this value represents
an invalid temperature reading!
This is a consequence of dealing with real data, and sometimes we need to be able to deal with anomalies such as this. In particular, we should make sure we fully understand the data we are using, and what it means. Otherwise, we run the risk of making assumptions and processing the data incorrectly.
In this case, we can fix our code by adding in a condition
(see climate_analysis-10.py):
# don't process invalid temperature readings of -9999
if fahr != -9999:
celsius = temp_conversion.fahr_to_celsius(fahr)
kelvin = temp_conversion.fahr_to_kelvin(fahr)
print('Max temperature in Celsius', celsius, 'Kelvin', kelvin)
So in this special case, we ensure that we aren’t processing these invalid values. In practice, we’d also need to make sure that any conclusions we may reach from processing the data in this way are also still valid.
Adding in a checks for the right number of arguments
But if we (or someone else) runs our script accidentally with no filename, we get:
Traceback (most recent call last):
File "climate_analysis.py", line 5, in <module>
filename = sys.argv[1]
IndexError: list index out of range
Since our filename is reading from an element in sys.argv that isn’t
present. This is not very helpful! To make it easier to diagnose
such problems, we can implement a simple check to ensure the right
number of arguments are given to our script.
Insert the following before the filename assignment (see climate_analysis-11.py):
script = sys.argv[0]
assert len(sys.argv) == 2, script + ": requires filename"
Here, we use the Python assert statement, which accepts a condition and a
string to output if the condition is false, to assert that we have only
2 arguments. If not, an error message is displayed.
Now when we run it with no arguments, we get:
Traceback (most recent call last):
File "climate_analysis.py", line 5, in <module>
assert len(sys.argv) == 2, script + ": requires filename"
AssertionError: climate_analysis.py: requires filename
More helpful! We could make this even more helpful by providing more information about the file that is required.
Using our script in a pipeline
Currently, our script outputs some friendly text to show what the data means. But when it comes to using it within a pipeline, where we might process the output data in some way, the additional text may make this more difficult.
Assuming we’ve documented our code properly and the nature of the output
is clearly understood, we can simplify the output by changing the
print() statement:
print(str(celsius)+", "+str(kelvin))
Here, we are using Python’s + operator to concatenate strings
together, so we can get output such as 20.561111111111114, 293.7111111111111.
We could run the script now in a pipeline, for example, to get the last
10 rows of output (see climate_analysis-12.py):
python climate_analysis.py ../data/sc_climate_data_1000.csv | tail -10
Or use grep to search the output for fahrenheit values that are equal to ‘14.85’:
python climate_analysis.py ../data/sc_climate_data_1000.csv | grep '14.85,'
We can now also do things like:
python climate_analysis.py ../data/sc_climate_data_1000.csv | wc -l
Which tells us the number of lines it processed, taking into account the -9999 values it ignored:
923
Just to note, there are some instances where we could use this with commands like head
instead, which may generate errors. Feel free to read the next section in the
tutorial which deals with how to handle them, but this is beyond the scope of this course
and we won’t cover it here.
The Right Way to Do It
If our programs can take complex parameters or multiple filenames, we shouldn’t handle
sys.argvdirectly. Instead, we should use Python’sargparselibrary, which handles common cases in a systematic way, and also makes it easy for us to provide sensible error messages for our users.
Dealing with pipeline errors
We could also run the script now in a pipeline, for example, to get the first 10 rows of output:
python climate_analysis.py ../data/sc_climate_data_1000.csv | head -10
But whilst we get our first 10 rows as expected, we now get a really odd error as well:
...
Traceback (most recent call last):
File "climate_analysis-12.py", line 25, in <module>
print(str(celsius)+", "+str(kelvin))
BrokenPipeError: [Errno 32] Broken pipe
Exception ignored in: <_io.TextIOWrapper name='<stdout>' mode='w' encoding='UTF-8'>
BrokenPipeError: [Errno 32] Broken pipe
This is an odd consequence of using Python in a command line pipeline —
it doesn’t cope with piping output to other commands very well. In essence, head gets
the first 10 lines it needs and terminates the pipe prematurely, before our program has
finished piping its output, which can cause this error. But it only happens on
Linux and Mac platforms!
We can fix this on these platforms by including the following at the top, after our
temp_conversion import (see climate_analysis-13.py):
import signal
signal.signal(signal.SIGPIPE, signal.SIG_DFL)
We’re telling our Python script to ignore any pipe errors — not ideal, but solves our problem.
Key Points
Reading and analysing Patient data using libraries
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Explain what a library is, and what libraries are used for.
- Load a Python library and use the things it contains.
- Read tabular data from a file.
- Select individual values and subsections from data.
- Perform operations on arrays of data.
This lesson presents an end-to-end scientific Python example, from analysing data (using a library), to visualisation (using a library).
We are studying inflammation in patients who have been given a new treatment for arthritis, and need to analyse the first dozen data sets of their daily inflammation. The data sets are stored in comma-separated values (CSV) format: each row holds information for a single patient, and the columns represent successive days. The first few rows of our first file look like this:
0,0,1,3,1,2,4,7,8,3,3,3,10,5,7,4,7,7,12,18,6,13,11,11,7,7,4,6,8,8,4,4,5,7,3,4,2,3,0,0
0,1,2,1,2,1,3,2,2,6,10,11,5,9,4,4,7,16,8,6,18,4,12,5,12,7,11,5,11,3,3,5,4,4,5,5,1,1,0,1
0,1,1,3,3,2,6,2,5,9,5,7,4,5,4,15,5,11,9,10,19,14,12,17,7,12,11,7,4,2,10,5,4,2,2,3,2,2,1,1
0,0,2,0,4,2,2,1,6,7,10,7,9,13,8,8,15,10,10,7,17,4,4,7,6,15,6,4,9,11,3,5,6,3,3,4,2,3,2,1
0,1,1,3,3,1,3,5,2,4,4,7,6,5,3,10,8,10,6,17,9,14,9,7,13,9,12,6,7,7,9,6,3,2,2,4,2,0,1,1
We want to:
- load that data into memory,
- calculate the average inflammation per day across all patients, and
- plot the result.
In order to load our inflammation data, we need to import a library called NumPy. In general you should use this library if you want to do fancy things with numbers, especially if you have matrices.
Let’s start by ensuring we are in the `swc-python-novice-websci/’ directory, e.g.:
$ pwd
And we should see:
/Users/nelle/swc-python-novice-websci
First, let’s go into the code subdirectory, and run the Python interpreter.
$ cd code
$ python
We can load NumPy using:
import numpy
Importing a library is like getting a piece of lab equipment out of a storage locker and setting it up on the bench. Once it’s done, we can ask the library to read our data file for us.
Just as we can assign a single value to a variable, we can also assign an array of values to a variable using the same syntax:
data = numpy.loadtxt(fname='../data/inflammation-01.csv', delimiter=',')
This statement doesn’t produce any output because assignment doesn’t display anything.
The expression numpy.loadtxt(...) is a function call
that asks Python to run the function loadtxt that belongs to the numpy library.
This dotted notation is used everywhere in Python
to refer to the parts of things as thing.component.
numpy.loadtxt has two parameters:
the name of the file we want to read,
and the delimiter that separates values on a line.
These both need to be character strings (or strings for short),
so we put them in quotes.
By default,
only a few rows and columns are shown
(with ... to omit elements when displaying big arrays).
To save space,
Python displays numbers as 1. instead of 1.0
when there’s nothing interesting after the decimal point.
Now that our data is in memory, we can start doing things with it.
If we want to check that our data has been loaded, we can print the variable’s value:
print(data)
array([[ 0., 0., 1., ..., 3., 0., 0.],
[ 0., 1., 2., ..., 1., 0., 1.],
[ 0., 1., 1., ..., 2., 1., 1.],
...,
[ 0., 1., 1., ..., 1., 1., 1.],
[ 0., 0., 0., ..., 0., 2., 0.],
[ 0., 0., 1., ..., 1., 1., 0.]])
Let’s ask what type of thing data refers to:
print(type(data))
<type 'numpy.ndarray'>
The output tells us that data currently refers to an N-dimensional array created by the NumPy library.
We can see what its shape is like this:
print(data.shape)
(60, 40)
This tells us that data has 60 rows and 40 columns, representing 60 patients over 40 days.
data.shape is a member of data,
i.e.,
a value that is stored as part of a larger value.
We use the same dotted notation for the members of values
that we use for the functions in libraries
because they have the same part-and-whole relationship.
If we want to get a single value from the matrix, we must provide an index in square brackets, just as we do in math:
print('first value in data:', data[0, 0])
first value in data: 0.0
print('middle value in data:', data[30, 20])
middle value in data: 13.0
The expression data[30, 20] may not surprise you,
but as with lists, data[0, 0] might.
So if we have an M×N array in Python,
its indices go from 0 to M-1 on the first axis
and 0 to N-1 on the second.
It takes a bit of getting used to,
but one way to remember the rule is that
the index is how many steps we have to take from the start to get the item we want.
In the Corner
What may also surprise you is that when Python displays an array, it shows the element with index
[0, 0]in the upper left corner rather than the lower left. This is consistent with the way mathematicians draw matrices, but different from the Cartesian coordinates. The indices are (row, column) instead of (column, row) for the same reason, which can be confusing when plotting data.
An index like [30, 20] selects a single element of an array,
but we can select whole sections as well.
For example,
we can select the first ten days (columns) of values
for the first four (rows) patients like this:
print(data[0:4, 0:10])
[[ 0. 0. 1. 3. 1. 2. 4. 7. 8. 3.]
[ 0. 1. 2. 1. 2. 1. 3. 2. 2. 6.]
[ 0. 1. 1. 3. 3. 2. 6. 2. 5. 9.]
[ 0. 0. 2. 0. 4. 2. 2. 1. 6. 7.]]
The slice 0:4 means, numpy selects items between boundries [0,4] and [0,10].
See slide Slicing a List Example I.
Again, this takes a bit of getting used to, but the rule is that the difference between the upper and lower bounds is the number of values in the slice.
We don’t have to start slices at 0:
print(data[5:10, 0:10])
[[ 0. 0. 1. 2. 2. 4. 2. 1. 6. 4.]
[ 0. 0. 2. 2. 4. 2. 2. 5. 5. 8.]
[ 0. 0. 1. 2. 3. 1. 2. 3. 5. 3.]
[ 0. 0. 0. 3. 1. 5. 6. 5. 5. 8.]
[ 0. 1. 1. 2. 1. 3. 5. 3. 5. 8.]]
We also don’t have to include the upper and lower bound on the slice. If we don’t include the lower bound, Python uses 0 by default; if we don’t include the upper, the slice runs to the end of the axis, and if we don’t include either (i.e., if we just use ‘:’ on its own), the slice includes everything:
small = data[:3, 36:]
print('small is:')
print(small)
small is:
[[ 2. 3. 0. 0.]
[ 1. 1. 0. 1.]
[ 2. 2. 1. 1.]]
Arrays also know how to perform common mathematical operations on their values. The simplest operations with data are arithmetic: add, subtract, multiply, and divide. When you do such operations on arrays, the operation is done on each individual element of the array. Thus:
doubledata = data * 2.0
will create a new array doubledata
whose elements have the value of two times the value of the corresponding elements in data:
print('original:')
print(data[:3, 36:])
print('doubledata:')
print(doubledata[:3, 36:])
original:
[[ 2. 3. 0. 0.]
[ 1. 1. 0. 1.]
[ 2. 2. 1. 1.]]
doubledata:
[[ 4. 6. 0. 0.]
[ 2. 2. 0. 2.]
[ 4. 4. 2. 2.]]
If, instead of taking an array and doing arithmetic with a single value (as above) you did the arithmetic operation with another array of the same size and shape, the operation will be done on corresponding elements of the two arrays. Thus:
tripledata = doubledata + data
will give you an array where tripledata[0,0] will equal doubledata[0,0] plus data[0,0],
and so on for all other elements of the arrays.
print('tripledata:')
print(tripledata[:3, 36:])
tripledata:
[[ 6. 9. 0. 0.]
[ 3. 3. 0. 3.]
[ 6. 6. 3. 3.]]
Often, we want to do more than add, subtract, multiply, and divide values of data. Arrays also know how to do more complex operations on their values. If we want to find the average inflammation for all patients on all days, for example, we can just ask the array for its mean value
print(data.mean())
6.14875
mean is a method of the array,
i.e.,
a function that belongs to it
in the same way that the member shape does.
If variables are nouns, methods are verbs:
they are what the thing in question knows how to do.
This is why data.shape doesn’t need to be called
(it’s just a thing)
but data.mean() does
(it’s an action).
It is also why we need empty parentheses for data.mean():
even when we’re not passing in any parameters,
parentheses are how we tell Python to go and do something for us.
NumPy arrays have lots of useful methods:
print('maximum inflammation:', data.max())
print('minimum inflammation:', data.min())
print('standard deviation:', data.std())
maximum inflammation: 20.0
minimum inflammation: 0.0
standard deviation: 4.613833197118566
When analyzing data, though, we often want to look at partial statistics, such as the maximum value per patient or the average value per day. One way to do this is to select the data we want to create a new temporary array, then ask it to do the calculation:
patient_0 = data[0, :] # 0 on the first axis, everything on the second
print('maximum inflammation for patient 0:', patient_0.max())
maximum inflammation for patient 0: 18.0
We don’t actually need to store the row in a variable of its own. Instead, we can combine the selection and the method call:
print('maximum inflammation for patient 3:', data[2, :].max())
maximum inflammation for patient 3: 19.0
What if we need the maximum inflammation for all patients, or the average for each day? As the diagram below shows, we want to perform the operation across an axis:

To support this, most array methods allow us to specify the axis we want to work on. If we ask for the average across axis 0 (representing the patients axis), we get:
print(data.mean(axis=0))
[ 0. 0.45 1.11666667 1.75 2.43333333 3.15
3.8 3.88333333 5.23333333 5.51666667 5.95 5.9
8.35 7.73333333 8.36666667 9.5 9.58333333
10.63333333 11.56666667 12.35 13.25 11.96666667
11.03333333 10.16666667 10. 8.66666667 9.15 7.25
7.33333333 6.58333333 6.06666667 5.95 5.11666667 3.6
3.3 3.56666667 2.48333333 1.5 1.13333333
0.56666667]
As a quick check, we can ask this array what its shape is:
print(data.mean(axis=0).shape)
(40,)
The expression (40,) tells us we have an N×1 vector,
so this is the average inflammation per day for all patients.
If we average across axis 1, we get:
print(data.mean(axis=1))
[ 5.45 5.425 6.1 5.9 5.55 6.225 5.975 6.65 6.625 6.525
6.775 5.8 6.225 5.75 5.225 6.3 6.55 5.7 5.85 6.55
5.775 5.825 6.175 6.1 5.8 6.425 6.05 6.025 6.175 6.55
6.175 6.35 6.725 6.125 7.075 5.725 5.925 6.15 6.075 5.75
5.975 5.725 6.3 5.9 6.75 5.925 7.225 6.15 5.95 6.275 5.7
6.1 6.825 5.975 6.725 5.7 6.25 6.4 7.05 5.9 ]
which is the average inflammation for each patient across all days.
Thin slices
From our previous topic, the expression
element[3:3]produces an empty string, i.e., a string that contains no characters. Ifdataholds our array of patient data, what doesdata[3:3, 4:4]produce? What aboutdata[3:3, :]?
Key Points
Data Visualisation
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Displaying simple graphs
- Plotting data using matplotlib library
- Analysing data from multiple files
The mathematician Richard Hamming once said,
“The purpose of computing is insight, not numbers,”
and the best way to develop insight is often to visualize data.
Visualization deserves an entire lecture (or course) of its own,
but we can explore a few features of Python’s matplotlib here.
While there is no “official” plotting library,
this package is the de facto standard.
First,
we will import the pyplot module from matplotlib
and use two of its functions to create and display a heat map of our data
from the previous topic:
from matplotlib import pyplot
pyplot.imshow(data)
pyplot.show()
pyplot keeps track of the graph as we are building it, so when we do pyplot.show() it’s
just showing us what’s been built so far.
Blue regions in this heat map are low values, while red shows high values. As we can see, inflammation rises and falls over a 40-day period.
Note that if we try and run pyplot.show() again, the graph doesn’t show. This is because
after it’s been displayed, matplotlib resets and clears the current graph. To see it
again, we need to generate the plot again, e.g.:
pyplot.imshow(data)
pyplot.show()
Let’s take a look at the average inflammation over time:
ave_inflammation = data.mean(axis=0)
pyplot.plot(ave_inflammation)
pyplot.show()
Here,
we have put the average per day across all patients in the variable ave_inflammation,
then asked pyplot to create and display a line graph of those values.
The result is roughly a linear rise and fall,
which is suspicious:
based on other studies,
we expect a sharper rise and slower fall.
Let’s have a look at two other statistics:
pyplot.plot(data.max(axis=0))
pyplot.show()
pyplot.plot(data.min(axis=0))
pyplot.show()
The maximum value rises and falls perfectly smoothly, while the minimum seems to be a step function. Neither result seems particularly likely, so either there’s a mistake in our calculations or something is wrong with our data.
It’s very common to create an alias for a library when importing it
in order to reduce the amount of typing we have to do.
Here are our three plots side by side using aliases for numpy and pyplot:
import numpy as np
from matplotlib import pyplot as plt
data = np.loadtxt(fname='../data/inflammation-01.csv', delimiter=',')
fig = plt.figure(figsize=(10.0, 3.0))
axes1 = fig.add_subplot(1, 3, 1)
axes2 = fig.add_subplot(1, 3, 2)
axes3 = fig.add_subplot(1, 3, 3)
axes1.set_ylabel('average')
axes1.plot(data.mean(axis=0))
axes2.set_ylabel('max')
axes2.plot(data.max(axis=0))
axes3.set_ylabel('min')
axes3.plot(data.min(axis=0))
plt.show()
Running the above code (present under code directory in the file three-plots.py) may throw the warning as below. If you see the warning, please ignore it.
`/Users/user/anaconda/lib/python3.4/site-packages/matplotlib/tight_layout.py:225: UserWarning: tight_layout : falling back to Agg renderer
warnings.warn("tight_layout : falling back to Agg renderer")`
tight_layout still works by falling back to a different way of generating the graph (the Agg renderer).
The call to loadtxt reads our data,
and the rest of the program tells the plotting library
how large we want the figure to be,
that we’re creating three sub-plots,
and what to draw for each one.
Make your own plot
Create a plot showing the standard deviation of the inflammation data for each day across all patients. Hint:
data.std(axis=0)gives you standard deviation.
Moving plots around
Modify the program to display the three plots on top of one another instead of side by side.
We now have almost everything we need to process all our data files. The only thing that’s missing is a library with a rather unpleasant name:
import glob
The glob library contains a single function, also called glob,
that finds files whose names match a pattern.
We provide those patterns as strings:
the character * matches zero or more characters,
while ? matches any one character.
We can use this to get the names of all the HTML files in the current directory:
print(glob.glob('*.html'))
['01-numpy.html', '02-loop.html', '03-lists.html', '04-files.html', '05-cond.html', '06-func.html', '07-errors.html', '08-defensive.html', '09-debugging.html', '10-cmdline.html', 'index.html', 'LICENSE.html', 'instructors.html', 'README.html', 'discussion.html', 'reference.html']
Your output may have been different it depends on what folder you are in and what filetype you search for. Try using different filetypes and see what you find eg.
print(glob.glob('*.py'))
As these examples show,
glob.glob’s result is a list of strings,
which means we can loop over it
to do something with each filename in turn.
In our case,
the “something” we want to do is generate a set of plots for each file in our inflammation dataset.
Let’s test it by analyzing the first three files in the list:
import glob
import numpy as np
from matplotlib import pyplot as plt
filenames = glob.glob('../data/inflammation-*.csv')
filenames.sort()
filenames = filenames[0:3]
for filename in filenames:
print(filename)
data = np.loadtxt(fname=filename, delimiter=',')
fig = plt.figure(figsize=(10.0, 3.0))
axes1 = fig.add_subplot(1, 3, 1)
axes2 = fig.add_subplot(1, 3, 2)
axes3 = fig.add_subplot(1, 3, 3)
axes1.set_ylabel('average')
axes1.plot(data.mean(axis=0))
axes2.set_ylabel('max')
axes2.plot(data.max(axis=0))
axes3.set_ylabel('min')
axes3.plot(data.min(axis=0))
fig.tight_layout()
plt.show()
inflammation-01.csv
inflammation-02.csv
inflammation-03.csv
Sure enough, the maxima of the first two data sets show exactly the same ramp as the first, and their minima show the same staircase structure; a different situation has been revealed in the third dataset, where the maxima are a bit less regular, but the minima are consistently zero.
Saving our Plots
We can also save our plots to disk. Let’s change our updated script to do that, by replacing plt.show() with fig.savefig(filename). But what should we use for a filename each time? A quick way would be to just use the filename variable, and append a .png to it. This will tell matplotlib to save a generated graph as a PNG image file.
Let’s do this now, e.g.:
import glob
import numpy as np
from matplotlib import pyplot as plt
filenames = glob.glob('../data/inflammation-*.csv')
filenames.sort()
filenames = filenames[0:3]
for filename in filenames:
print(filename)
data = np.loadtxt(fname=filename, delimiter=',')
fig = plt.figure(figsize=(10.0, 3.0))
axes1 = fig.add_subplot(1, 3, 1)
axes2 = fig.add_subplot(1, 3, 2)
axes3 = fig.add_subplot(1, 3, 3)
axes1.set_ylabel('average')
axes1.plot(data.mean(axis=0))
axes2.set_ylabel('max')
axes2.plot(data.max(axis=0))
axes3.set_ylabel('min')
axes3.plot(data.min(axis=0))
fig.tight_layout()
fig.savefig(filename + '.png')
If we rerun this script, we can see that our graphs have appeared as PNG files in the data directory, with the filenames inflammation-XX.csv.png.
Now we’re satisfied that this works for a few inflammation datasets, we can now remove the filenames = filenames[0:3] statement, which will allow the script to work over all the inflammation datasets, which will also appear in the data directory.
Key Points
Python Style Guide
Overview
Teaching: min
Exercises: minQuestions
Objectives
Learning Objectives
- Python coding conventions
This is taken from PEP-008: Python Style Guide. It is a semi-official guide to Python coding conventions.
We should stick to this unless we have hard data that proves something else is better.
Basic layout is as below:
- Indent blocks using four spaces
- Keep lines less than 80 characters long
- Separate functions with two blank lines
- Separate logical chunks of long functions with a single blank line
- Put comments on lines of their own, rather than to the right of code
Here are some basic python style rules listed in a table below:
| Rule | Good | Bad |
|---|---|---|
| No whitespace immediately inside parentheses or before the parenthesis starting indexing or slicing | max(candidates[sublist]) |
max( candidates[ sublist ] ) , max (candidates [sublist] ) |
| No whitespace immediately before comma or colon | if limit > 0: print minimum, limit |
if limit > 0 : print minimum , limit |
| Use space around arithmetic and in-place operators | x += 3 * 5 |
x+=3*5 |
| No spaces when specifying default parameter values | def integrate(func, start=0.0, interval=1.0) |
def integrate(func, start = 0.0, interval = 1.0) |
Never use names that are distinguished only by "l", "1", "0", or "O" |
tempo_long and tempo_init |
tempo_l and tempo_1 |
| Short lower-case names for modules (i.e., files) | geology |
Geology or geology_package |
| Upper case with underscores for constants | TOLERANCE or MAX_AREA |
Tolerance or MaxArea |
| Camel case for class names | SingleVariableIntegrator |
single_variable_integrator |
| Lowercase with underscores for function and method names | divide_region |
divRegion |
| and member variables | max_so_far |
maxSoFar |
Use is and is not when comparing to special values |
if current is not None: |
if current != None: |
Use isinstance when checking types |
if isinstance(current, Rock): |
if type(current) == Rock: |
Table 8.1: Basic Python Style Rules
Key Points
Challenges
Overview
Teaching: min
Exercises: minQuestions
Objectives
Python basics: Variables, Objects, Arrays, Lists etc
What’s inside the box?
Draw diagrams showing what variables refer to what values after each statement in the following program:
weight = 70.5 age = 35 # Take a trip to the planet Neptune weight = weight * 1.14 age = age + 20
Sorting out references
What does the following program print out?
first, second = 'Grace', 'Hopper' third, fourth = second, first print(third, fourth)
Arrays, Lists, etc.
Slicing strings
What is the value of
element[:4]? What aboutelement[4:]? Orelement[:]?What is
element[-1]? What iselement[-2]? Given those answers, explain whatelement[1:-1]does.
Slicing From the End
Use slicing to access only the last four characters of a string or entries of a list.
string_for_slicing = "Observation date: 02-Feb-2013" list_for_slicing = [["fluorine", "F"], ["chlorine", "Cl"], ["bromine", "Br"], ["iodine", "I"], ["astatine", "At"]]"2013" [["chlorine", "Cl"], ["bromine", "Br"], ["iodine", "I"], ["astatine", "At"]]Would your solution work regardless of whether you knew beforehand the length of the string or list (e.g. if you wanted to apply the solution to a set of lists of different lengths)? If not, try to change your approach to make it more robust.
Overloading
+usually means addition, but when used on strings or lists, it means “concatenate”. Given that, what do you think the multiplication operator*does on lists? In particular, what will be the output of the following code?counts = [2, 4, 6, 8, 10] repeats = counts * 2 print(repeats)
[2, 4, 6, 8, 10, 2, 4, 6, 8, 10][4, 8, 12, 16, 20][[2, 4, 6, 8, 10],[2, 4, 6, 8, 10]][2, 4, 6, 8, 10, 4, 8, 12, 16, 20]The technical term for this is operator overloading: a single operator, like
+or*, can do different things depending on what it’s applied to.
Repeating actions using loops
From 1 to N
Python has a built-in function called
rangethat creates a list of numbers:range(3)produces[0, 1, 2],range(2, 5)produces[2, 3, 4]. Usingrange, write a loop to print the first 3 natural numbers:1 2 3
Turn a String Into a List
Use a for-loop to convert the string “hello” into a list of letters:
["h", "e", "l", "l", "o"]Hint: You can create an empty list like this:
my_list = []
Computing powers with loops
Exponentiation is built into Python:
print(5 ** 3) 125Write a loop that calculates the same result as
5 ** 3using multiplication (and without exponentiation).
Reverse a string
Write a loop that takes a string, and produces a new string with the characters in reverse order, so
NewtonbecomesnotweN.
Making choices
How many paths?
Which of the following would be printed if you were to run this code? Why did you pick this answer?
- A
- B
- C
- B and C
if 4 > 5: print('A') elif 4 <= 5: print('B') elif 4 < 5: print('C')
What Is Truth?
TrueandFalseare special words in Python calledbooleanswhich represent true and false statements. However, they aren’t the only values in Python that are true and false. In fact, any value can be used in aniforelif. After reading and running the code below, explain what the rule is for which values are considered true and which are considered false.if '': print('empty string is true') if 'word': print('word is true') if []: print('empty list is true') if [1, 2, 3]: print('non-empty list is true') if 0: print('zero is true') if 1: print('one is true')
Modularising your code using functions
Combining Strings
“Adding” two strings produces their concatenation:
'a' + 'b'is'ab'. Write a short function calledfencethat takes two parameters calledoriginalandwrapperand returns a new string that has the wrapper character at the beginning and end of the original. A call to your function should look like this:print(fence('name', '*'))*name*
How do function parameters work?
We actually used the same variable name
fahrin our main code and and the function. But it’s important to note that even though they share the same name, they don’t refer to the same thing. This is because of variable scoping.Within a function, any variables that are created (such as parameters or other variables), only exist within the scope of the function.
For example, what would be the output from the following:
f = 0 k = 0 def multiply_by_10(f): k = f * 10 return k multiply_by_10(2) multiply_by_10(8) print(k)
- 20
- 80
- 0
Does the sum of a list equal a given value?
Write a function to take a list of numbers and another value, and return whether or not the sum of the list of numbers is equal to that value.
Following the function definition, a call to your function should look like this:
is_sum_equal([1,2,3], 6)) True is_sum_equal([2,4,6], 100) FalseThis is really useful, since it means we don’t have to worry about conflicts with variable names that are defined outside of our function that may cause it to behave incorrectly.
Readable Code
Revise a function you wrote for one of the previous exercises to try to make the code more readable. Then, collaborate with one of your neighbors to critique each other’s functions and discuss how your function implementations could be further improved to make them more readable.
How to deal with problems in your code
Identifying Variable Name Errors
- Read the code below (or open the file
error_name_ch.pyin code folder), and (without running it) try to identify what the errors are.- Run the code, and read the error message. What type of
NameErrordo you think this is? In other words, is it a string with no quotes, a misspelled variable, or a variable that should have been defined but was not?- Fix the error.
- Repeat steps 2 and 3, until you have fixed all the errors.
for number in range(10): # use a if the number is a multiple of 3, otherwise use b if (Number % 3) == 0: message = message + a else: message = message + "b" print(message)
Identifying Syntax Errors
- Read the code below (or open the file
error_syntax_ch.pyin code folder), and (without running it) try to identify what the errors are.- Run the code, and read the error message. Is it a
SyntaxErroror anIndentationError?- Fix the error.
- Repeat steps 2 and 3, until you have fixed all the errors.
def another_function print("Syntax errors are annoying.") print("But at least python tells us about them!") print("So they are usually not too hard to fix.")
Identifying Index Errors
- Read the code below, and (without running it) try to identify what the errors are.
- Run the code, and read the error message. What type of error is it?
- Fix the error.
seasons = ['Spring', 'Summer', 'Fall', 'Winter'] print('My favorite season is ', seasons[4])
Reading Error Messages
Read the python code (or open the file
error_index_ch.pyin code folder) and the resulting traceback below, and answer the following questions:
- How many levels does the traceback have?
- What is the function name where the error occurred?
- On which line number in this function did the error occurr?
- What is the type of error?
- What is the error message?
# This code has an intentional error. Do not type it directly; # use it for reference to understand the error message below. def print_message(day): messages = { "monday": "Hello, world!", "tuesday": "Today is tuesday!", "wednesday": "It is the middle of the week.", "thursday": "Today is Donnerstag in German!", "friday": "Last day of the week!", "saturday": "Hooray for the weekend!", "sunday": "Aw, the weekend is almost over." } print(messages[day]) def print_friday_message(): print_message("Friday") print_friday_message()Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in print_friday_message File "<stdin>", line 11, in print_message KeyError: 'Friday'
Debug with a Neighbour
Take a function that you have written today, and introduce a tricky bug. Your function should still run, but will give the wrong output. Switch seats with your neighbor and attempt to identify - or debug - the problem that they introduced into their function.
Not Supposed to be the Same
You are assisting a researcher with Python code that computes the Body Mass Index (BMI) of patients (open the file
error_silent_ch.pyin code folder). The researcher is concerned because all patients seemingly have identical BMIs, despite having different physiques. BMI is calculated as weight in kilograms divided by the the square of height in metres.patients = [[70, 1.8], [80, 1.9], [150, 1.7]] def calculate_bmi(weight, height): return weight / (height ** 2) for patient in patients: height, weight = patients[0] bmi = calculate_bmi(height, weight) print("Patient's BMI is: %f" % bmi)Patient's BMI is: 21.604938 Patient's BMI is: 21.604938 Patient's BMI is: 21.604938
Reading and analysing Patient data using libraries
Thin slices
From our previous topic challenges, the expression
element[3:3]produces an empty string, i.e., a string that contains no characters. Ifdataholds our array of patient data, what doesdata[3:3, 4:4]produce? What aboutdata[3:3, :]?
Data Visualisation
Make your own plot
Create a plot showing the standard deviation of the inflammation data for each day across all patients. Hint:
data.std(axis=0)gives you standard deviation.
Moving plots around
Modify the program to display the three plots on top of one another instead of side by side.
Making choices
How many paths?
Which of the following would be printed if you were to run this code? Why did you pick this answer?
- A
- B
- C
- B and C
if 4 > 5: print('A') elif 4 <= 5: print('B') elif 4 < 5: print('C')
Key Points
Why Python?
Overview
Teaching: min
Exercises: minQuestions
Objectives
Why Python?
- Free, well-documented, runs almost everywhere
- Large (and growing) user base among researchers and scientists
- Simple, readable, flexible, powerful language and easier for beginners to grasp
- Great for team working
- Python aim - only one way to do something
- Programs look very similar, easy for others to read
- Want to teach basic programming concepts that can be applied to other programming languages
What can you use it for?
- Almost anything - it’s general purpose!
- Used in many fields
- Bioinformatics, Biology, Data visualisation, Engineering, Software development, etc.
- Used for processing data, general scripting, mapping, web applications, frameworks, numerical processing, education, HPC, at Google, …
Python is up and coming!
- Based on Southampton PhD students software usage survey conducted by SSI’s Policy researchers:

We’ll be teaching Python 3
- Python 3 is currently the standard version
- We’ll teach using version 3!
- Python 3 has many advantages over Python 2
- Many consistency improvements - removing redundancy
- In places, simply more sensible e.g. integer division
- Python 2 support will end in 2020
- ‘Short version: Python 2.x is legacy, Python 3.x is the present and future of the language’
- For new projects, seriously consider Python 3!
Learning objectives
- how to assign values to variables, simple operations
- how to repeat actions with loops
- how to make choices using conditionals
- why we should divide programs into small, single-purpose blocks of code
- how to build a program, step by step, to do basic analysis on some climate data
- how we should analyse and fix errors in our programs
- how to read and analyse patient data using libraries
- how to visualise data using libraries
Turning on Python Interpreter
- The interpreter provides an interactive environment to play with the language
- Mac/Linux: Open a terminal window and type python3
- Windows: Open Git Bash and type python
- At the prompt type ‘hello world!’

Why indentation?
- Studies show that’s what people actually pay attention to + Every textbook on C or Java has examples where indentation and bracing don’t match
- Doesn’t matter how much indentation you use, but the whole block must be consistent
- Python Style Guide (PEP 8) recommends 4 spaces
- And no tab characters
Indexing a List Example I
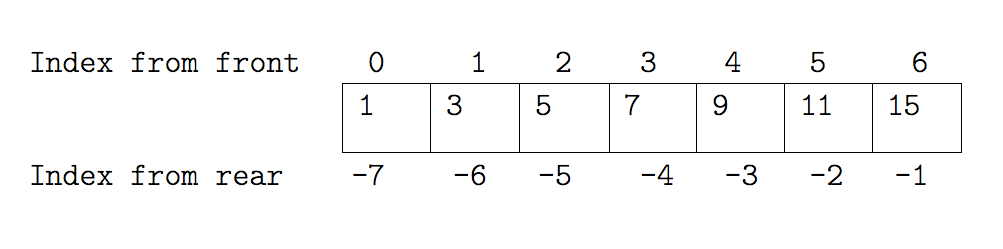
Indexing a List Example II
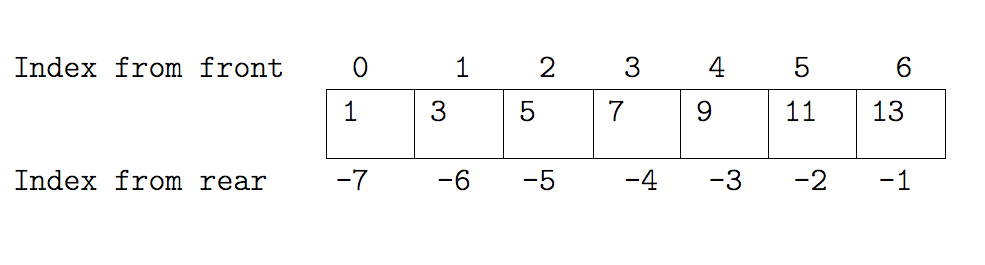
Slicing a List Example I

Slicing a List Example II

NumPy Arrays
-
NumPy arrays and operations on arrays of data
Indexing in a NumPy 2D array
- The indices are (row, column) instead of (column, row).
- Example Patient inflammation data who were given treatment for arthritis:
- Rows: Hold information for a single patient
- Columns: Represent successive days
Cont..
Wrap-up Challenge: Connecting the dots
Write a python script (function) for Fahrenheit to Celsius temperature conversion and stores the output in a file.
- Hint (Tools to be used):
- Unix pipes and filters
- Python functions
- Command-line programs
- Using Fahr_to_kelvin() and Kelvin_to_celsius() functions
Thank You!
Key Points