
Version Control with Git
- Tracking Changes
Learning Objectives
- Go through the modify-add-commit cycle for single and multiple files.
- Explain where information is stored at each stage.
Tracking changes to files
Add to Version Control
We can tell Git to track a file using git add:
$ git add climate_analysis.py temp_conversion.pyand then check that the right thing happened:
$ git statusOn branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: climate_analysis.py
new file: temp_conversion.pyGit now knows that it’s supposed to keep track of climate_analysis.py and temp_conversion.py, but it hasn’t recorded these changes as a commit yet:
Initial Commit
To get it to do that, we need to run one more command:
$ git commit -m "Initial commit of climate analysis code"We use the -m flag (for “message”) to record a short, descriptive comment that will help us remember later on what we did and why.
If we just run git commit without the -m option, Git will launch nano (or whatever other editor we configured at the start) so that we can write a longer message.
Good commit messages start with a brief (<50 characters) summary of changes made in the commit.
NOT “Bug Fixes” or “Changes”!
If you want to go into more detail, add a blank line between the summary line and your additional notes.
[master (root-commit) a10bd8f] Initial commit of climate analysis code
2 files changed, 50 insertions(+)
create mode 100644 climate_analysis.py
create mode 100644 temp_conversion.pyWhen we run git commit, Git takes everything we have told it to save by using git add and stores a copy permanently inside the special .git directory. This permanent copy is called a revision and its short identifier is a10bd8f. (Your revision will have different identifier.)
If we run git status now:
$ git status# On branch master
nothing to commit, working directory cleanit tells us everything is up to date.
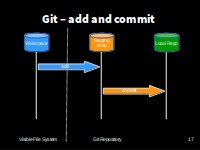
Add and Commit
Git has a special staging area where it keeps track of things that have been added to the current change set but not yet committed. git add puts things in this area, and git commit then copies them to long-term storage (as a commit)

Exploring history #1
Review the Log
If we want to know what we’ve done recently, we can ask Git to show us the project’s history using git log:
$ git logcommit a10bd8f6192f9ab29b1821d7d7929fbf6484686a
Author: John R <j.robinson@software.ac.uk>
Date: Mon Dec 7 14:13:32 2015 +0000
Initial commit of climate analysis codegit log lists all revisions committed to a repository in reverse chronological order (most recent at the top).
The listing for each revision includes
- the revision’s full identifier (which starts with the same characters as the short identifier printed by the
git commitcommand earlier), - the revision’s author,
- when it was created,
- the log message Git was given when the revision was committed.
Modify a file (1)
Now suppose we add more information, a Docstring, to the top of one of the files:
$ nano climate_analysis.py""" Climate Analysis Tools """When we run git status now, it tells us that a file it already knows about has been modified:
$ git statusOn branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: climate_analysis.py
no changes added to commit (use "git add" and/or "git commit -a")The last line is the key phrase: “no changes added to commit”.
So, while we have changed this file, but we haven’t told Git we will want to save those changes (which we do with git add) much less actually saved them (which we do with git commit).
It’s important to remember that git only stores changes when you make a commit
Review Changes and Commit
It is good practice to always review our changes before saving them. We do this using git diff. This shows us the differences between the current state of the file and the most recently commited version:
$ git diffdiff --git a/climate_analysis.py b/climate_analysis.py
index 277d6c7..d5b442d 100644
--- a/climate_analysis.py
+++ b/climate_analysis.py
@@ -1,3 +1,4 @@
+""" Climate Analysis Tools """
import sys
import temp_conversion
import signalThe output is cryptic because it is actually a series of commands for tools like editors and patch telling them how to reconstruct one file given the other.
The key things to note are:
- Line 1: The files that are being compared (a/ and b/ are labels, not paths)
- Line 2: The two hex strings on the second line which parts of the hashes of the files being compares
- Line 5: The lines that have changed. (It’s complex)
- Below that, the changes - note the ‘+’ marker which shows an addtion
After reviewing our change, it’s time to commit it:
$ git commit -m "Add Docstring"On branch master
Changes not staged for commit:
modified: climate_analysis.py
no changes added to commitWhoops: Git won’t commit because we didn’t use git add first. Let’s fix that:
$ git add climate_analysis.py
$ git commit -m "Add Docstring"[master 6077ba7] Add Docstring
1 file changed, 1 insertion(+) ** Recapping add / commit**
Git insists that we add files to the set we want to commit before actually committing anything because we may not want to commit everything at once.
For example, suppose we might have fixed a bug in some existing code, but we might have added new code that’s not ready to share
Exploring history #1
One more addition
Let’s add another line to the end of the file:
$ nano climate_analysis.py# TODO(js-robinson): Add call to process rainfallCheck what’s changed with diff:
$ git diffdiff --git a/climate_analysis.py b/climate_analysis.py
index d5b442d..c463f71 100644
--- a/climate_analysis.py
+++ b/climate_analysis.py
@@ -26,3 +26,5 @@ for line in climate_data:
kelvin = temp_conversion.fahr_to_kelvin(fahr)
print(str(celsius)+", "+str(kelvin))
+
+# TODO(js-robinson): Add call to process rainfallSo far, so good: we’ve added one line to the end of the file (shown with a + in the first column).
Now let’s put that change in the staging area (or add it to the change set) and see what git diff reports:
$ git add climate_analysis.py
$ git diffThere is no output:
git diff shows us the differences between the working copy and what’s been added to the change set in staging area.
However, if we do this:
$ git diff --stageddiff --git a/climate_analysis.py b/climate_analysis.py
index d5b442d..c463f71 100644
--- a/climate_analysis.py
+++ b/climate_analysis.py
@@ -26,3 +26,5 @@ for line in climate_data:
kelvin = temp_conversion.fahr_to_kelvin(fahr)
print(str(celsius)+", "+str(kelvin))
+
+# TODO(me): Add call to process rainfallit shows us the difference between the last committed change and what’s in the staging area.
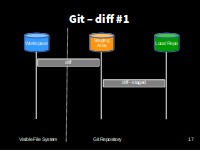
Git diff #1
Let’s commit our changes:
$ git commit -m "Add rainfall processing placeholder"[master dab17a9] Add rainfall processing placeholder
1 file changed, 2 insertions(+)check our status:
$ git status# On branch master
nothing to commit, working directory cleanand now look at the history of what we’ve done so far:
$ git logcommit dab17a9f0d2e8e598522a1c06dcaf396084f60e6
Author: John R <j.robinson@software.ac.uk>
Date: Mon Dec 7 14:57:39 2015 +0000
Add rainfall processing placeholder
commit 6077ba7b614de65fa28cc58c6cb8a4c55735a9d8
Author: John R <j.robinson@software.ac.uk>
Date: Mon Dec 7 14:40:02 2015 +0000
Add Docstring
commit a10bd8f6192f9ab29b1821d7d7929fbf6484686a
Author: John R <j.robinson@software.ac.uk>
Date: Mon Dec 7 14:13:32 2015 +0000
Initial commit of climate analysis code
To recap, when we want to add changes to our repository, we first need to add the changed files to the staging area (git add) and then commit the staged changes to the repository (git commit):